7 Best Gemini Cost Optimization Tools for 2026
12 min read
Tools

Table of Contents
Comparing the top Gemini cost optimization tools for 2026 are 1. Amnic, 2. Portkey, 3. Helicone, 4. LiteLLM, 5. OpenRouter, 6. Cloudflare AI Gateway, and 7. Langfuse.
Gemini cost optimization tools cut your API bill by pulling three levers: caching repeated context, routing simple calls to a cheaper Flash or Flash-Lite model, and batching non-urgent work. The need is real because Google bills Gemini per token, output tokens cost several times more than input tokens, and a single monthly total cannot tell you which feature, team, or surface burned the spend.
These tools split into two jobs. Gateways and routers reduce the bill at request time. A FinOps layer attributes the bill, budgets it, and reports it the way finance already handles cloud cost. Amnic ranks first for that second job, then connects to Gemini and Vertex AI alongside OpenAI, Anthropic, and Bedrock plus AWS, Azure, and GCP so AI and cloud reconcile in one place.
Here is a detailed comparison of the best Gemini cost optimization software for 2026, starting with Amnic. Book a 30-minute Amnic demo to see Gemini cost optimization in action, then where your wider cloud spend leaks, before the call ends.
Top Gemini Cost Optimization Tools at a Glance
Amnic: Gemini and Vertex AI spend attribution, model budgets, and anomaly alerts inside a full FinOps platform that also covers your cloud bill.
Portkey: AI gateway with semantic caching, model routing, budgets, and guardrails across Gemini and a large model catalog.
Helicone: Drop-in proxy that logs Gemini cost and latency and serves repeated requests from cache with one line of setup.
LiteLLM: Open-source proxy that routes and load-balances across Gemini, Vertex AI, and 100+ providers with per-key budget caps.
OpenRouter: Routing layer that sends each call to the cheapest qualifying provider, Gemini models included, with a hard price ceiling.
Cloudflare AI Gateway: Lightweight proxy in front of the Gemini API that adds caching, rate limiting, and cost analytics at no extra fee.
Langfuse: Open-source tracing platform with Gemini token cost tracking, prompt versioning, and evaluations.
Gemini Cost Optimization Tools Comparison Table
Information reflects vendor sources as of June 2026. Confirm current pricing with the vendor.
Tool | Best for | Gemini coverage and cost levers | Free option | Pricing model |
|---|---|---|---|---|
Amnic | FinOps and finance teams owning AI plus cloud spend | Gemini, Vertex AI, OpenAI, Anthropic, Bedrock; attribution, model budgets, anomaly alerts | One-month trial | % of monitored spend |
Portkey | Multi-model teams wanting a production gateway | Semantic caching, routing, budgets, guardrails across Gemini and Vertex | 10k logs/mo | Tiered, from $49/mo |
Helicone | Fast request-level cost visibility plus caching | Gemini logging, response caching, rate limits, cost analytics | 10k requests/mo | Tiered, from $79/mo |
LiteLLM | Engineers standardizing many providers behind one API | Routing, load balancing, per-key budgets across Gemini and Vertex | Open-source self-host | Free OSS + enterprise |
OpenRouter | Routing every call to the cheapest provider | Lowest-cost routing for Gemini models, price ceilings, quality-cost dial | Pay as you go | Passthrough + credit fee |
Cloudflare AI Gateway | Adding caching and analytics to the Gemini API fast | Response caching, rate limiting, logging, cost analytics | Free with account | Free + provider passthrough |
Langfuse | Deep tracing and prompt-level cost data | Trace-level Gemini cost, prompt versioning, evals | 50k units/mo | Tiered + self-host |
What Are Gemini Cost Optimization Tools?
Gemini cost optimization tools are software that reduce what you pay Google for Gemini API calls and make the remaining spend visible, owned, and predictable. They turn a single monthly token total into a bill you can cut at the source and assign to the team or feature that caused it. The same control extends across every model you run inside a GenAI cost management platform.
Every Gemini response returns usage metadata with prompt, candidate, and cached token counts. Optimization tools act on that flow in three places. They cache repeated context so the model is not billed in full for the same system prompt, where cached input runs up to 90% cheaper than standard input. They route simple calls to a cheaper Flash or Flash-Lite tier, which costs a fraction per token of the flagship Pro model. They move non-urgent jobs to Batch Mode for a flat discount.
For a FinOps lead or AI platform engineer, the harder half is accountability. They need to answer who spent what on Gemini and why, then tie it to cost allocation so a feature that burns tokens shows up against the revenue it earns. The seven tools below cover both halves, starting with the finance layer.
The Gemini Savings Stack: What Each Lever Is Worth
Before you buy a tool, it helps to know which lever moves the bill the most, because the tools below are just ways to pull these levers at scale. Google documents most of these in its own developer guidance, and stacking them is how teams take a large share off the bill in a quarter without users noticing.
Model right-sizing is the biggest single win: Most calls do not need Gemini Pro. Routing the simple ones to Flash or Flash-Lite can turn a four-figure monthly workload into a two-figure one, since the lighter tiers cost far less per token. This is the first thing to fix, and most teams over-provision here.
Context caching is close to free money on repeated prompts: Implicit caching is on by default for Gemini 2.5 and newer, and explicit caching lets you pin a long document or system prompt with a time-to-live. Cached input is discounted heavily, but only when the shared context sits at the start of the request and clears the minimum token count.
Batch Mode is the lazy 50% off: Anything that does not need an instant answer, nightly classification, bulk tagging, document extraction, runs asynchronously within 24 hours for half price. Teams skip it because it needs a queue, not because it is hard.
The thinking budget controls the expensive half: Gemini 2.5 models reason before they answer, and those thinking tokens bill as output, which costs several times more than input. Setting a thinking budget per call stops a simple question from quietly running up a flagship-priced answer.
The surface you pick changes the controls: The same model is reachable through Google AI Studio and through Vertex AI, and the two differ on budgets, batch handling, and provisioned throughput. Choosing the right one is a cost decision before any tool is involved.
A tool earns its place by automating one or more of these levers at scale, rather than asking an engineer to remember them on every call. A finance layer earns its place differently, by proving the savings actually held once the quarter closes, which is the part the gateways skip. The rest of this guide covers both kinds, starting with the finance layer and the seven tools that handle these jobs.
How We Evaluated These Tools
Cost-reduction levers: does it actually cut the bill through caching, routing, or batching, not just chart it.
Gemini coverage: how well it handles Gemini models, cached tokens, the usage metadata, and both the Gemini API and Vertex AI surfaces.
Attribution granularity: can it split Gemini cost by team, feature, user, or customer, not only by model.
Budget and governance: can it cap spend per team or model before the invoice lands.
Deployment fit: managed, open-source, or self-hosted for data control.
Finance connection: whether Gemini spend joins the wider cost practice and unit economics, or stays stuck in engineering.
Best Gemini Cost Optimization Tools Reviewed
1. Amnic
Best for: FinOps and finance teams that need Gemini spend to behave like every other governed cost line, with attribution and budgets the CFO can read.
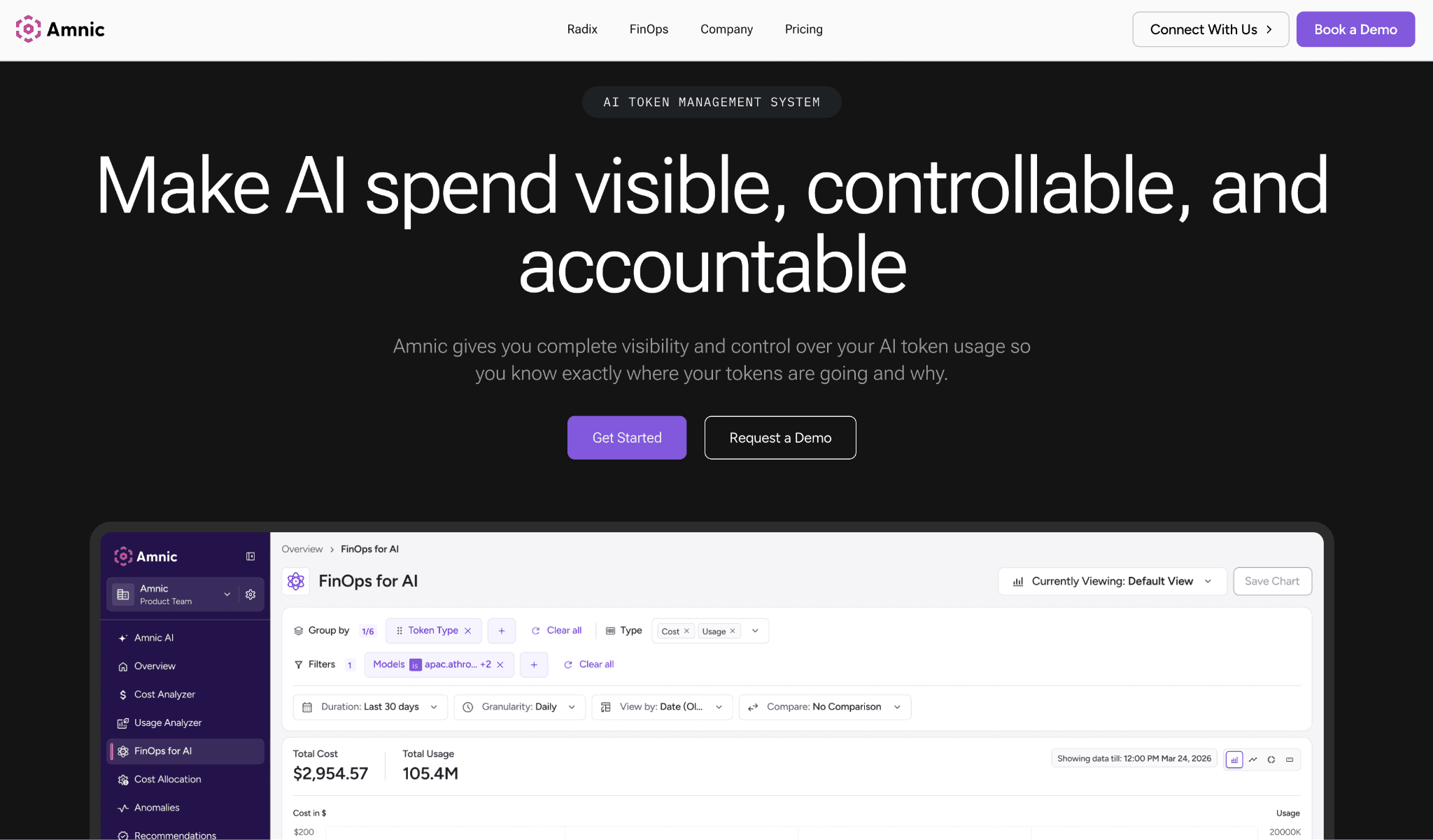
Amnic tracks input and output token consumption across Gemini, Vertex AI, OpenAI, Anthropic, and Amazon Bedrock, then attributes it to teams, users, and cost centers for real chargeback. Budgets sit across teams and models and trip before the invoice, not after.
The platform is agentless and read-only, so it reads provider and billing data without write access to your stack. Because Gemini spend lives in the same place as AWS, Azure, and GCP cost, finance reconciles AI and cloud together instead of in two disconnected tools. That is the gap most gateways leave open, since they reduce the bill but never tie it back to the business.
Key features:
Tracks input and output tokens per call across Gemini, Vertex AI, OpenAI, Anthropic, and Bedrock, so every provider rolls into one number instead of five dashboards
Maps that spend back to the team, feature, or customer that caused it, which is what makes real chargeback possible rather than a guess
Lets you set budgets per team and per model that alert and trip before the invoice lands, not three weeks after
Flags cost spikes the moment they start with anomaly detection, so a runaway agent loop on Gemini does not quietly run all weekend
Shows cost and margin per feature, so you can see which AI feature actually pays for itself and which is a money pit
Puts Gemini and Vertex AI spend right next to AWS, Azure, and GCP cost in a view finance already reads
Reads data agentless and read-only, with SOC 2, ISO, and GDPR posture, so security signs off without a long review
Pricing: Amnic charges a percentage of the spend it monitors, roughly 0.25% to 1%, so the cost scales with the bill it helps you cut instead of a flat per-seat fee. A one-month free trial is available.
Pros:
It answers the question finance actually asks, who spent this and on what, instead of charting a total nobody can break down
AI and cloud cost sit in one place, so month-end stops being a reconciliation between two tools
Read-only access means engineering never has to hand over write keys just to get visibility
Cons:
It governs and attributes spend rather than routing or caching calls, so you still want a gateway alongside it for request-time cuts
Percentage pricing is worth a sizing conversation once your bill gets very large
Amnic suits the team that has to explain the Gemini line to finance. Start a free Amnic trial to attribute your AI spend in days.
2. Portkey
Best for: Engineering teams running many models in production that want caching, routing, and budgets in one gateway.
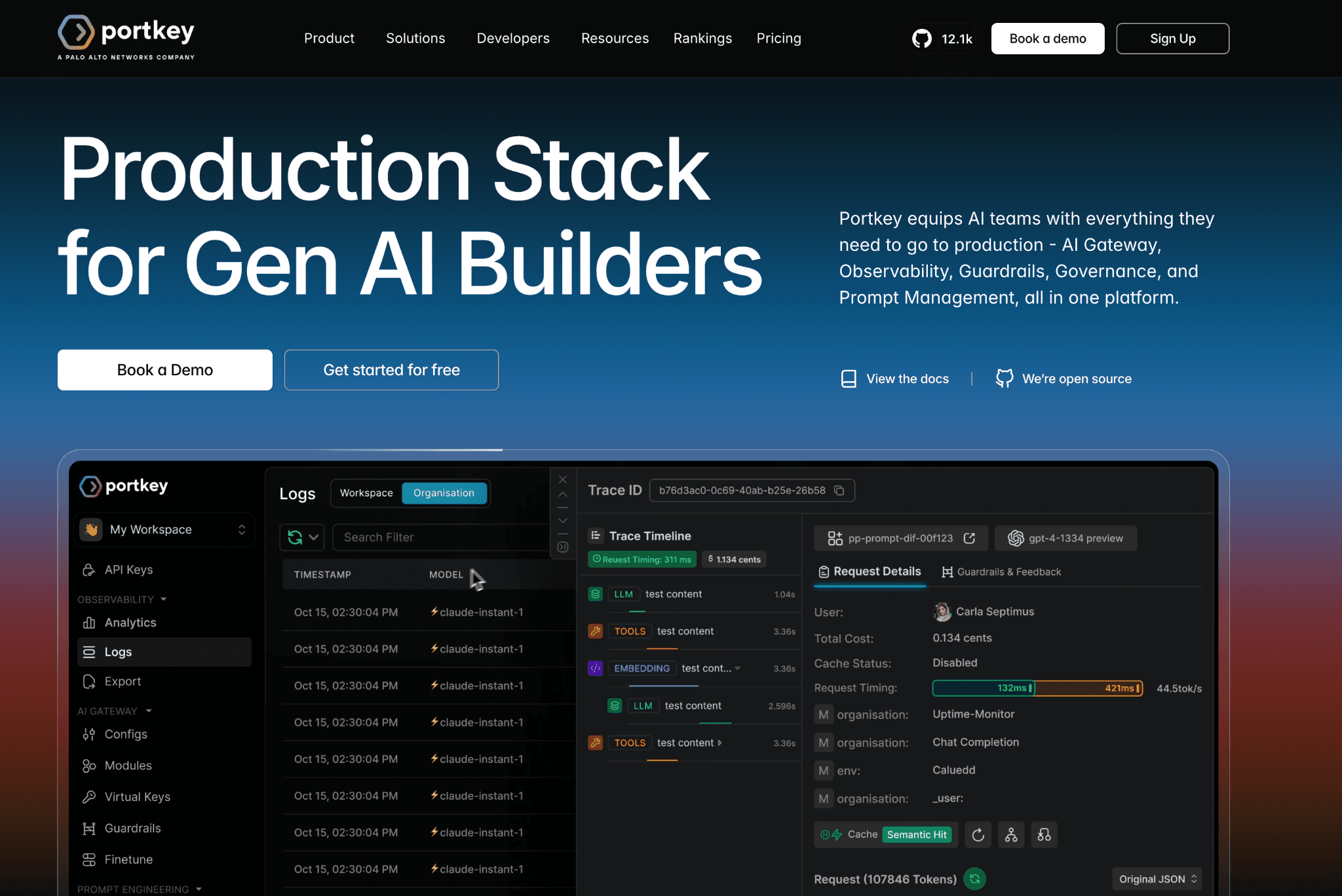
Portkey sits in front of your model calls as a gateway and tracks the token spend on every request, so you can see Gemini cost build up live and attribute it by model, key, or team. On top of that visibility it applies semantic caching, which returns a stored answer when a new prompt is close enough to a previous one rather than only on an exact match. That fuzzy match helps repetitive workloads like support, where users ask the same thing in different words, and it shows up directly as lower token cost.
Around the cost data, it adds routing, fallbacks, virtual keys, and real-time budget alerts that cap token spend per key or team, plus production controls like guardrails and PII redaction. It covers Gemini, Vertex AI, and a very large model catalog, so Gemini calls share one control plane and one cost view with the rest of your providers. Its token cost tracking is request-time and engineering-facing, so many teams still pair it with a FinOps for AI layer for finance-grade attribution.
Key features:
Semantic caching that matches prompts by meaning, so a slightly reworded question still hits the cache instead of paying full price again
Model routing with automatic fallbacks, so a Gemini outage reroutes to another model instead of erroring out
Budget limits per key and per team with alerts, which stops one runaway service from eating the whole quota
Production guardrails including PII redaction and jailbreak detection, handled at the gateway rather than in app code
Virtual keys, so you can hand a team its own scoped access without sharing the real Google credentials
A large model catalog behind one endpoint, so Gemini and everything else share one control plane
Real-time spend tracking you can watch as traffic flows
Pricing: The free Developer tier includes 10,000 logs per month with short retention. Paid plans start around $49 per month for the Production tier, and Enterprise is priced on request.
Pros:
Production controls extend past cost into guardrails and PII handling at the gateway
Semantic caching reduces spend on repeated and reworded prompts
One gateway spans many providers, so the setup is not tied to Gemini alone
Cons:
The free tier stops logging after 10,000 records a month, so most of your traffic goes dark until you pay
It controls cost at request time but does not attribute it, so finance still needs a separate view
3. Helicone
Best for: Teams that want Gemini cost and latency visibility fast, with caching as a bonus.

Helicone is a proxy you add with roughly one line of setup, after which every Gemini request is logged with input, output, token counts, latency, and cost. The analytics view makes it easy to spot a spend spike or a slow endpoint, which is the first step in any LLM cost comparison exercise.
Its gateway layer also caches repeated requests, which the vendor cites as cutting roughly 20 to 30% of API cost on repetitive traffic. Helicone leans toward observability rather than aggressive routing, so teams chasing the deepest cuts often pair it with a router. It is a low-effort way to read where Gemini spend goes before adding heavier tooling.
Key features:
A one-line proxy change to start, so you get data the same afternoon you install it
Full request and response logging, which is what you want the first time a bill jumps and you have no idea why
Response caching that serves repeat calls from store instead of re-billing them
Cost, token, and latency analytics in one view, so a spike and a slowdown are easy to spot
Rate limiting and custom property tags, so you can slice Gemini spend by whatever label matters to you
Session and trace views built for agents and multi-step chains, not just single calls
Alerting when cost or latency drifts, before it shows up on the invoice
Pricing: The free Hobby plan covers 10,000 requests per month with short retention. The Pro plan is around $79 per month, and a Team plan adds compliance features.
Pros:
Setup is light, so cost data appears soon after install
Caching lowers spend on repeated requests
The free tier covers small workloads
Cons:
It leans observability, so for aggressive routing or deep cuts you will add a second tool
Per-request logging costs climb once you are at high volume
4. LiteLLM
Best for: Engineers who want one OpenAI-compatible API across Gemini, Vertex AI, and many providers with budget caps built in.
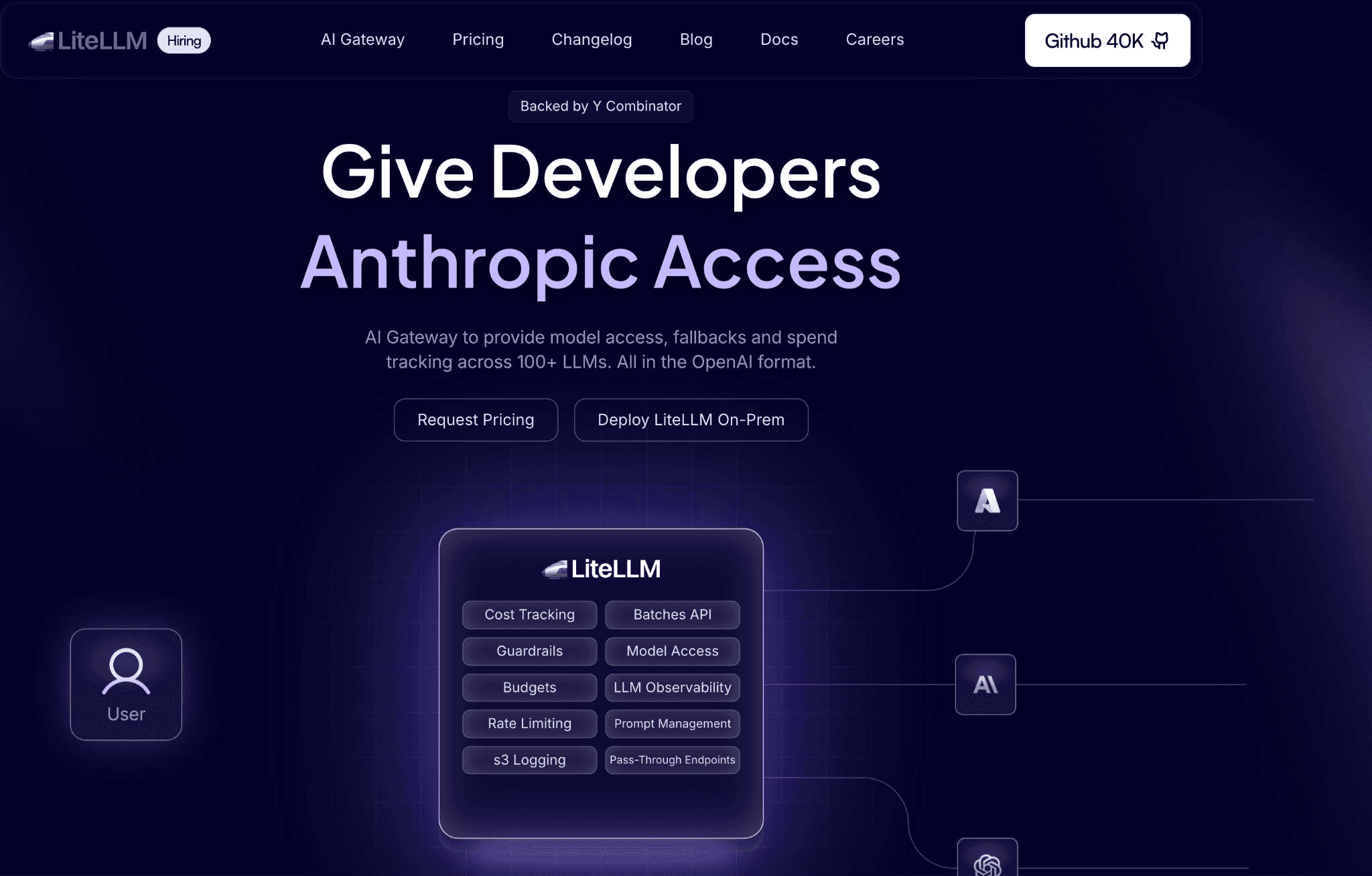
LiteLLM is an open-source proxy that wraps 100+ providers, Gemini and Vertex AI included, behind a single OpenAI-style endpoint, so you can switch or load-balance models without rewriting code. Its main cost lever is routing, sending traffic across models and providers, with budget and rate limits set per team, user, or API key.
It supports Redis-based caching for exact matches, with semantic caching available as a secondary feature. Because it is free to self-host as a Docker container, the trade-off is operational: you run and maintain it. Teams already standardizing their stack often place LiteLLM at the gateway and feed its spend data into FinOps tools for AI cost management for reporting.
Key features:
One OpenAI-compatible endpoint in front of Gemini, Vertex AI, and 100+ providers, so swapping a model is a config change, not a code rewrite
Routing and load balancing across models, so you can shift traffic to whatever is cheapest or fastest that day
Budgets and rate limits set per key, per user, and per team, enforced at the proxy
Access keys you can issue and revoke without touching the underlying Google project
Redis-backed caching for exact-match prompts, with semantic caching available if you wire it up
Built-in spend tracking and logs, so the gateway doubles as a usage record
Runs as a Docker container you host yourself, which keeps data inside your perimeter
Pricing: The open-source proxy is free to self-host. An enterprise edition with support and extra controls is priced on request.
Pros:
Covers a wide provider list behind one API, with Gemini and Vertex included
The core is free and open-source, so there is no license to clear before testing
Budget controls are granular down to the individual key
Cons:
You own the uptime, upgrades, and scaling, which is real work if no one wants to run it
Caching is exact-match first; semantic matching is more of a bolt-on than a core feature
5. OpenRouter
Best for: teams that want every call routed to the cheapest qualifying provider, Gemini models included, with a hard price cap.
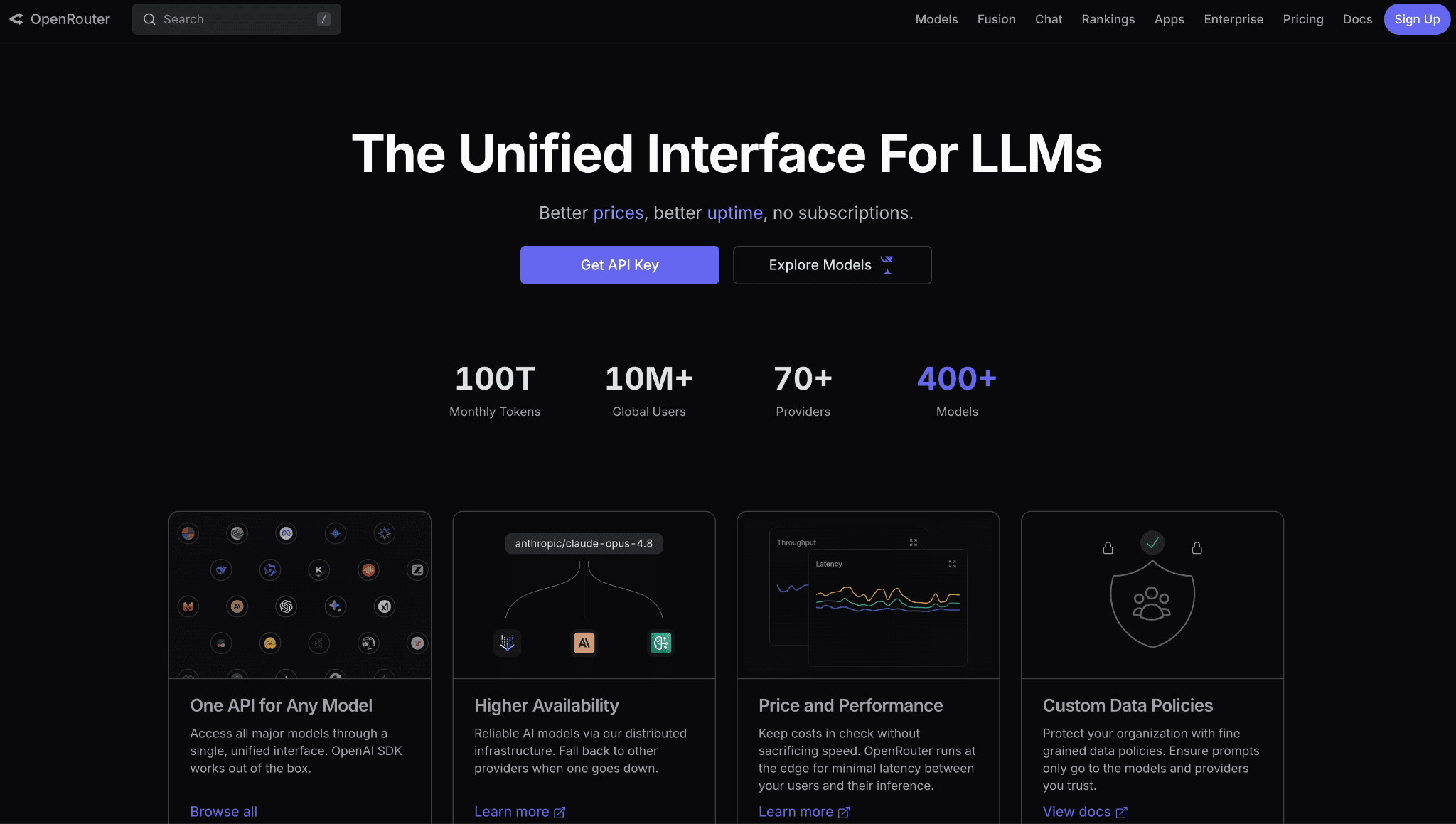
OpenRouter is a routing layer across hundreds of models that, by default, weights cheaper providers more heavily and lets you append a floor setting to always pick the lowest-cost option for a given model. A max-price control acts as a hard budget cap, failing a request instead of overspending, which is a clean guardrail for cost-sensitive pipelines.
Its Auto Router exposes a cost-quality dial so you can bias toward cheaper or stronger models per call, switching a simple task to Gemini Flash-Lite and a hard one to Pro. OpenRouter passes through provider pricing without markup and earns revenue through credit and usage fees instead. It is a request-time cost tool, not an attribution platform, so Gemini spend reporting still belongs elsewhere, for example a page on Gemini API pricing for rate context.
Key features:
Routing that defaults to cheaper providers and lets you pin a model to its lowest-cost host with a floor setting
A hard max-price ceiling per request, so a call fails rather than quietly overspending your budget
An Auto Router with a cost-quality dial, so you decide per call whether to favor Flash-Lite or Pro
Hundreds of models reachable through one API, Gemini tiers among them, including a set of free options for testing
Bring-your-own-key support, so you can route through your own Google contracts
Passthrough pricing, meaning you pay the listed rate with no markup on tokens
One billing relationship instead of separate accounts at every provider
Pricing: Model rates pass through with no markup. OpenRouter takes about 5.5% when you buy credits, and a 5% fee applies to bring-your-own-key usage past the first million requests a month.
Pros:
You pay the listed provider rate on tokens, with the platform's cut sitting in the fees instead
The price ceiling and cheapest-provider routing serve as a guardrail for cost-sensitive jobs
The model selection is wide
Cons:
The credit and BYOK fees are small per call but add up once you are at serious volume
It cuts the bill but keeps no record of who spent what, so attribution lives somewhere else
6. Cloudflare AI Gateway
Best for: teams that want caching, rate limiting, and cost analytics in front of the Gemini API without standing up new infrastructure.
Cloudflare AI Gateway is a thin proxy you point your Gemini calls through, after which it logs every request with token counts, cost, and latency, then serves repeat prompts from its cache. Because it runs on Cloudflare's edge, adding it is a URL change rather than a deployment, so it puts a control layer in front of Google AI Studio traffic with minimal setup.
On top of caching it adds rate limiting, request retries, and fallbacks across providers, so a Gemini error can fail over without breaking the app. It connects spend across Gemini and the other major models, though it stays an engineering-facing analytics and control layer, so finance-grade attribution still sits with a dedicated AI cost visibility tools workflow.
Key features:
A drop-in proxy in front of the Gemini API, so you add cost control with a URL change and no new servers
Response caching at the edge, which serves repeated prompts without re-billing the tokens
Rate limiting per app or key, so a buggy client cannot run the bill up unchecked
Request logging with cost, token, and latency analytics in one dashboard
Retries and provider fallbacks, so a transient Gemini error does not surface to users
Coverage across Gemini and the other major providers behind one gateway
Bring-your-own-key support, so you keep your own Google billing relationship
Pricing: The gateway itself is free with a Cloudflare account, and you keep paying Google directly for the underlying Gemini tokens. Persistent logs and higher-volume features draw on Cloudflare's paid Workers and logging tiers.
Pros:
Fast to add and free to start, with no infrastructure to run
Edge caching and rate limiting handle both spend and abuse in one layer
Runs on widely used edge infrastructure
Cons:
It is a request-time control layer, so it does not attribute Gemini spend to teams or features
The deepest features assume you are already in the Cloudflare ecosystem
7. Langfuse
Best for: teams that want trace-level Gemini cost data alongside prompt management and evaluations.

Langfuse is an open-source tracing platform that records each Gemini call as a span with token cost, then ties that to prompt versions and evaluation scores. That trace-level view helps you find the prompt or chain that quietly drives spend, which is a different angle from gateway caching or routing.
It pairs cost data with prompt versioning and evals, so you can test a cheaper prompt and see both the cost and the quality change before shipping. Cloud and self-hosted options exist, though self-hosting carries real infrastructure overhead. Langfuse measures and improves spend rather than cutting it at the gateway, so it complements a router and an AI agents for FinOps workflow.
Key features:
Records every Gemini call as a span with its token cost, so you can trace spend down to the exact prompt or chain step
Prompt versioning, so you can see which version of a prompt got more expensive and when
Evaluations sitting next to cost, so a cheaper prompt is judged on quality before it ships
An open-source core you can read and extend
Cloud or self-hosted, depending on whether data residency matters to you
Support for the major model providers, Gemini included
Dataset and experiment tooling for testing changes on real traffic
Pricing: The free Hobby plan covers 50,000 units per month. The Core cloud plan starts around $29 per month. Self-hosting is free, but it needs Postgres, ClickHouse, Redis, and object storage to run, so the infrastructure is not free.
Pros:
Useful for pinning down the exact prompt behind a cost
Open-source with a free tier for early builds
Cost and quality can be tested side by side before shipping
Cons:
It shows you the spend; it does not cache or route to cut it
Self-hosting is a heavy lift once you add up the four services it depends on
Gemini's Native Cost Tools on Google Cloud
Gemini cost optimization tools include Google's own native solutions, such as Gemini Cloud Assist and the AI Cost Summary Agent, alongside third-party platforms like Amnic that monitor token spend, track anomalies, and control cloud cost.
The work splits into two areas, and your starting point depends on which one you own. The first is managing Gemini API and inference cost, where you control tokens, models, and request tiers. The second is using Gemini-powered agents to cut broader Google Cloud spend, where the model reads your bill and finds the waste.
Before you shortlist anything, settle two questions. Is your primary focus API development and token usage, or Google Cloud infrastructure cost? And which models are you running today, the high-volume Flash and Flash-Lite tiers or the heavier Pro tier? Those two answers decide whether you reach for a developer-side lever or a cloud-side agent first. If your stack also runs GPT models, the watching side is mapped out in OpenAI cost monitoring tools.
Google Cloud Native Tools (for GCP workflows)
Gemini Cloud Assist sits inside Cloud Billing and the FinOps hub, where it summarizes the cost drivers behind a spike, flags idle or oversized resources, and drafts the billing reports a finance team would otherwise build by hand. It reads spend in plain language, so a budget owner can ask why a number moved without writing a query. Google offers it at no additional cost, which makes it a reasonable first look for teams already on GCP.
The AI Cost Summary Agent goes narrower, scanning Gemini API and Vertex AI usage to pinpoint what drove a recent jump in AI spend. It breaks the bill down by model and API key and separates input-token cost from output-token cost, which is exactly where most Gemini surprises hide. For finance-grade attribution across AI and cloud together, teams pair it with a dedicated AI cost tracking tools layer that ties spend to teams and features.
API Inference and Model Optimization (for developers)
Model selection is the lever with the largest payoff, since routing high-volume, simple traffic to Flash-Lite or Flash instead of Pro cuts the per-token rate sharply. Flex Inference adds a second lever, a synchronous, cost-optimized tier that trades some latency and reliability for roughly 50% off standard pricing on latency-tolerant work.
Priority Inference is its opposite, charging a premium for the highest reliability on critical, interactive apps. Teams running open models on their own accelerators face a parallel set of choices in GPU cost optimization tools.
Context caching rounds out the developer levers by reusing large system prompts and reference documents across requests, so repeated context is billed at a discount instead of full price each call. Implicit caching applies automatically on Gemini 2.5 and newer, while explicit caching lets you pin content with a time-to-live for a guaranteed cut. The trade-off is structure, since the shared context has to sit at the start of the request to qualify.
API Cost Controls
Batch processing is the simplest control to switch on, running bulk and non-urgent jobs asynchronously within 24 hours at a steep discount on standard token pricing. It needs a queue rather than a code change, which is the only reason most teams leave it unused. Pair it with Flex for latency-tolerant work so the discounts stack instead of overlap.
Google AI Studio spend caps close the gap on the budget side, letting you set a firm monthly dollar limit so a runaway script or a bad deploy cannot produce a surprise invoice. Caps stop the spend at the account level, but they do not tell you who spent the money, which is why attribution still belongs with a FinOps platform.
Treat caps as a backstop, not a substitute for ownership. Teams that need the same view into a Claude bill can start with Anthropic cost visibility tools.
How to Choose the Right Gemini Cost Optimization Tool
You need to explain the Gemini bill to finance: choose Amnic for attribution, budgets, and one view across AI and cloud.
You run many models in production: choose Portkey for caching, routing, and guardrails in one gateway.
You want quick cost visibility with light caching: choose Helicone for one-line logging.
You are standardizing providers in code: choose LiteLLM for one API across Gemini and Vertex with per-key budgets.
You want the cheapest provider on every call: choose OpenRouter for floor routing and price ceilings.
You want edge caching with no new infrastructure: choose Cloudflare AI Gateway in front of the Gemini API.
You want to find the prompt behind the spend: choose Langfuse for trace-level cost.
You run on Google Cloud and want native, no-cost insight: start with Gemini Cloud Assist and the AI Cost Summary Agent before adding third-party tools.
Common Mistakes When Choosing Gemini Cost Optimization Tools
Treating visibility as optimization: A dashboard that shows the bill does not lower it. Pair an observability tool with a router or caching layer, and connect both to a cost attribution view so the savings are owned.
Ignoring Batch Mode: Moving non-urgent jobs to asynchronous processing earns a flat 50% discount on token pricing, which no third-party tool can beat. Use it before adding more software.
Leaving the thinking budget uncapped: Gemini 2.5 reasoning tokens bill as output and cost several times more than input, so an uncapped thinking budget is a silent cost driver. Set it per call first.
Buying a gateway and forgetting finance: Routing cuts the invoice but leaves no record of who spent what. Add a cloud budgeting and reporting layer so the savings hold over time.
Why Decision Makers Choose Amnic for Gemini Cost Optimization
Amnic owns the part the gateways and native agents leave behind: turning Gemini spend into an attributed, budgeted, reported cost line that finance trusts. Gateways cut the bill at request time and Google's own agents explain GCP cost, but neither maps spend to the team, feature, or customer that caused it. That mapping is what turns a token total into a number the business can act on, and it is the job Amnic is built for.
One view for AI and cloud. Gemini, Vertex AI, OpenAI, Anthropic, and Amazon Bedrock spend sits next to AWS, Azure, and GCP, so AI cost is reconciled with the rest of the bill, not in a separate tool.
Attribution and budgets that hold. Spend maps to teams, features, and cost centers, with budgets that trip before the invoice and alerts on cost spikes.
Read-only and agentless. Amnic reads provider and billing data without write access, so engineering keeps control while finance gets the numbers.
Because the same view covers other providers, a team comparing Anthropic API pricing against Gemini sees every bill in one place rather than three consoles.
Book a 30-minute Amnic demo to see your Gemini and cloud spend attributed in one view.
Frequently Asked Questions
What are Gemini cost optimization tools?
They are software that lowers your Gemini API bill through context caching, model routing, and batching, then makes the remaining spend visible and assignable to the team or feature that caused it.
What is the fastest way to cut a Gemini bill?
Route simple calls to a cheaper Flash or Flash-Lite model and cache repeated context. Cached input is discounted heavily, and a Flash-Lite call costs a fraction per token of the flagship Pro tier.
Does context caching with Gemini cost extra?
Implicit caching is on by default for Gemini 2.5 and newer at no extra write cost. Explicit caching adds a storage charge for how long the cache is held, but cached input tokens are billed at a steep discount.
How much can model routing save on Gemini?
It depends on traffic mix, but sending most simple queries to Flash or Flash-Lite instead of Pro commonly cuts the input-token bill by a large share without a visible quality drop on those calls.
Do I need a separate tool for Gemini cost attribution?
Often yes. Gateways and routers reduce the bill but rarely attribute it. A FinOps platform like Amnic assigns Gemini spend to teams and features and ties it to revenue.
Is Gemini Batch Mode worth using?
For non-urgent work, yes. It processes requests asynchronously within 24 hours at a 50% discount, which is usually the single largest lever before adding third-party tools.
Should I use the Gemini API or Vertex AI to control cost?
Use the Gemini API through Google AI Studio for fast, lower-volume work. Move to Vertex AI when you need enterprise budgets, provisioned throughput, and tighter governance over large or regulated workloads.
See Your Gemini Spend in One View
Caching, routing, and batching cut the Gemini bill at request time. Owning that spend, budgeting it, and reporting it to finance is the other half, and it is where most teams stall. Amnic brings Gemini cost together with your cloud bill, attributes it to teams and features, and flags spikes before the invoice. Teams cutting a Claude bill in parallel can pull the same levers, broken down in Anthropic cost optimization tools.
Better visibility and management into AI Tokens?
Start with a 30 day trial
Connect leading LLMs
24 hour time to value
Stay ahead of AI Spend

Make AI spend visible, controllable, and accountable.
Gain insights into your AI token costs at a team, customer, business unit and individual user level to measure and manage AI utilization.
Recommended Articles

8 Best Llama Cost Management Tools in 2026
Read More

8 Best Amazon Bedrock Cost Optimization Tools for 2026
Read More

7 Best Amazon Bedrock Cost Monitoring Tools
Read More

8 Best Gemini Cost Visibility Tools for 2026
Read More

7 Best Multimodal Cost Optimization Tools for 2026
Read More

5 Best Anthropic Cost Allocation Tools for 2026
Read More






