Top 8 AI Token Management Tools for 2026
11 min read
Tools

Table of Contents
Comparing the top AI token management tools for 2026 are 1. Amnic, 2. Helicone, 3. Portkey, 4. LiteLLM, 5. Langfuse, 6. Datadog LLM Observability, 7. Arize Phoenix and 8. TrueFoundry.
AI token management tools track, attribute and govern the input, output and reasoning tokens your applications send to model providers. They exist because a provider dashboard shows one total number and cannot tell you which team, feature or customer drove the bill. That blind spot grows fast when output and reasoning tokens cost several times more than input tokens.
Most tools below were built by and for engineers, so they answer technical questions about traces and latency. Amnic sits at the finance layer, where token spend is attributed, budgeted and reported the way a finance team already handles cloud cost. The eight tools split across gateways, observability platforms and finance-grade governance.
Best AI Token Management Software at a Glance
Amnic: Token spend attribution, model budgets and finance-grade chargeback inside a full FinOps platform.
Helicone: Drop-in proxy that logs token cost, latency and caching with one line of setup.
Portkey: AI gateway with routing, budgets and guardrails across a very large model catalog.
LiteLLM: Open-source proxy that normalizes 100+ providers to an OpenAI-compatible API with spend tracking.
Langfuse: Open-source tracing platform with token cost tracking, evaluations and prompt management.
Datadog LLM Observability: LLM cost and trace monitoring inside the wider Datadog APM stack.
Arize Phoenix: Open-source, OpenTelemetry-native tracing and evaluation for agent workflows.
TrueFoundry: Enterprise LLM gateway with access control, budgets and self-hosted deployment.
AI Token Management Tools Comparison Table
Information reflects vendor sources as of June 2026. Confirm current pricing with the vendor.
Tool | Coverage | Token-specific features | Free option | Pricing model | Best for |
|---|---|---|---|---|---|
Amnic | OpenAI, Anthropic, Gemini, Bedrock + AWS/Azure/GCP | Team and cost-center attribution, model budgets, anomaly alerts, per-feature profitability | One-month trial | % of monitored spend | FinOps and finance teams owning AI spend |
Helicone | 100+ models via proxy | Per-request logging, caching, custom property tags | Free 10k requests/mo | Per logged request | Fast request-level visibility |
Portkey | 1,600+ models | Routing, budgets, guardrails, virtual keys | Free 10k requests/mo | Tiered + open-source | Multi-model gateway control |
LiteLLM | 100+ providers | Spend tracking, budgets, rate limits per key | Open-source self-host | Free OSS + enterprise | Engineers standardizing APIs |
Langfuse | All major providers | Trace-level cost, prompt versioning, evals | Free 50k units/mo | Tiered + MIT self-host | Deep tracing and data control |
Datadog LLM Observability | 800+ models | Per-request cost estimation, span breakdown | Trial | Usage-based add-on | Existing Datadog shops |
Arize Phoenix | OTel-instrumented models | Span-level cost, evals, drift analysis | Open-source self-host | Free OSS + AX paid | Open-source agent tracing |
TrueFoundry | Multi-provider gateway | Budgets, RBAC, PII guardrails | Trial | Usage-based + enterprise | Regulated enterprise platforms |
What Are AI Token Management Tools?
AI token management tools are software that measures, attributes and controls the tokens your applications exchange with model providers so cost stops being a surprise. They turn raw token counts into spend you can assign, budget and question, the same discipline a FinOps team brings to the cloud.
Each API response returns a usage object with input and output token counts and some models report reasoning tokens on top. A token management tool captures that object at the gateway or trace level, applies current model rates and rolls the result into dashboards, budgets and alerts.
For a FinOps lead or AI platform engineer, the job is accountability. They need to answer who spent what and why, then tie it to cost allocation so a feature that burns tokens shows up against the revenue it earns.
How We Evaluated These Tools
Attribution granularity: can it split token cost by team, feature, user or customer, not only by model.
Multi-provider coverage: does it unify OpenAI, Anthropic, Gemini and Bedrock in one view.
Budget and governance: can it cap spend per team or model before the invoice arrives.
Real-time signal: how fast it surfaces a spend spike or a runaway agent loop.
Deployment fit: managed, open-source or self-hosted for data control.
Finance connection: whether token data joins the wider cost practice and unit economics or stays stuck in engineering.
Best AI Token Management Tools Reviewed
1. Amnic
Best for: FinOps and finance teams that need AI token spend to behave like every other governed cost line, with attribution and budgets the CFO can read.
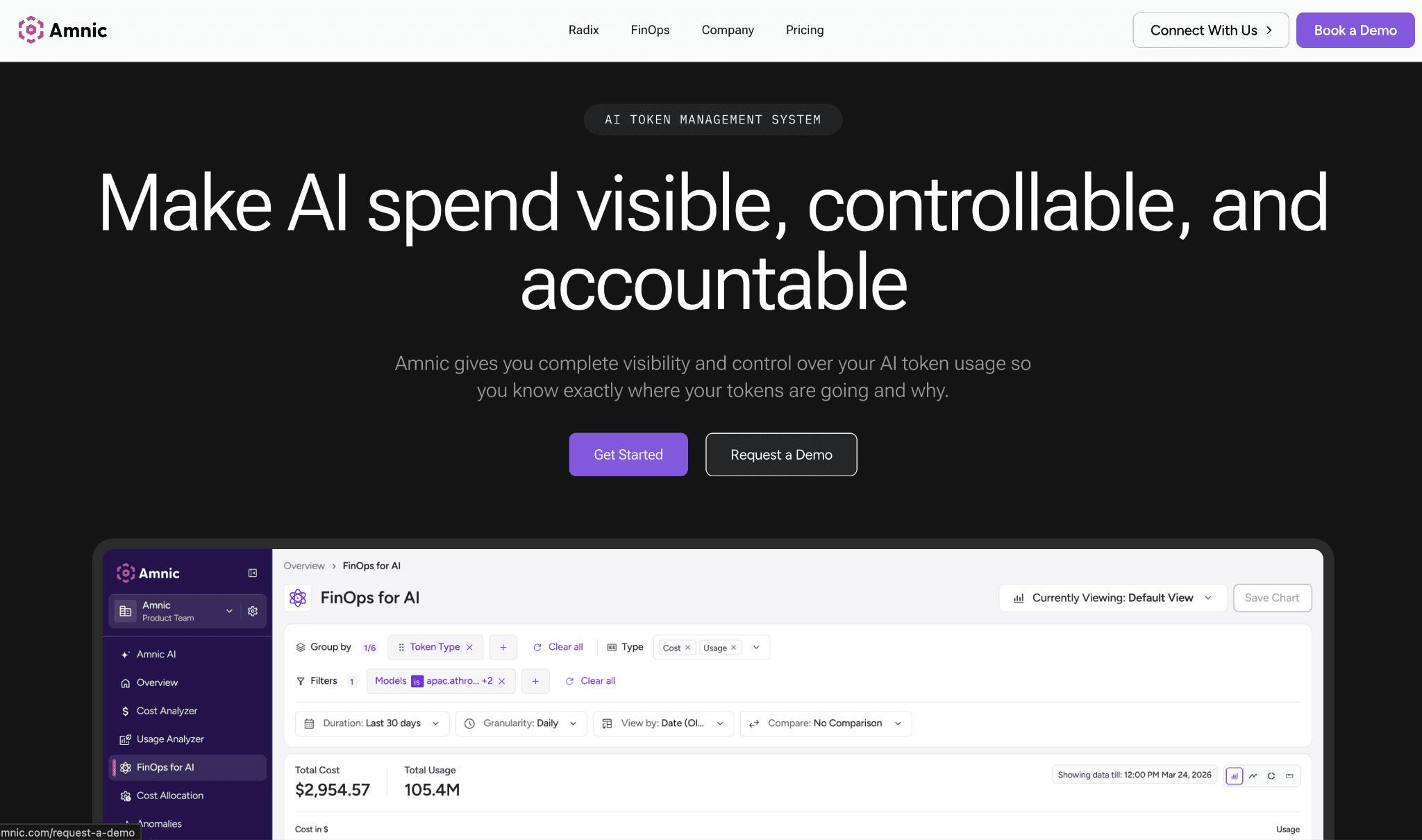
Amnic tracks input and output token consumption across OpenAI, Anthropic, Gemini and Amazon Bedrock, then attributes it to teams, users and cost centers for real chargeback. Budgets sit across teams and models and trip before the invoice, not after.
The platform is agentless and read-only, so it reads provider and billing data without write access to your stack. Because token spend lives in the same place as AWS, Azure and GCP cost, finance reconciles AI and cloud together instead of in two disconnected tools.
Key features:
Input and output token tracking across OpenAI, Anthropic, Gemini and Bedrock
Token spend attribution to teams, users and cost centers
Budget limits across teams and models with pre-invoice enforcement
Real-time anomaly detection on token cost spikes
Per-feature token cost and profitability analysis (beta)
Prompt efficiency comparison across models (beta)
Unified view of AI token spend and multi-cloud cost in one platform
Agentless, read-only integration with no infrastructure write access
Natural-language agents (X-Ray, Insights, Governance, Reporting) for FinOps workflows
SOC 2 Type II, ISO 27001 and GDPR aligned
Pricing: Amnic charges a percentage of monitored spend, roughly 0.25% to 1%, with a one-month startup trial and no credit card. Enterprise tiers add cost experts and custom scope.
Pros:
Finance reads spend as team and cost-center chargeback, with no log-to-report translation step
One pane for AI and cloud, so month-end reconciliation stops needing two separate tools
Stakeholder views and natural-language agents mean a CFO does not wait on engineering for a number
Cons:
The optimization layer (prompt efficiency, per-feature profitability) is in beta
More than a solo developer needs if the goal is just a quick per-call log
2. Helicone
Best for: Engineering teams that want per-request token visibility in an afternoon, without instrumenting their codebase.

Helicone is a proxy that sits in front of your model calls. You change the base URL and it starts logging tokens, cost and latency for every request, which makes it the fastest way to leave a provider dashboard behind.
Custom properties let you tag requests by user or feature and built-in caching trims repeat spend. It stays lightweight, which is also its ceiling, since the deeper governance you get from FinOps tools for AI cost management is not its focus.
Key features:
One-line proxy integration with no code instrumentation
Per-request logging of tokens, cost and latency
Prompt caching to cut repeat spend
Custom properties for per-user and per-feature tagging
Rate limiting, retries and request control
Session and trace grouping for multi-step agents
Provider-agnostic across major LLM APIs
Open-source core with a self-host option
Pricing: A free tier covers 10,000 requests per month with two seats. Paid plans scale by logged requests, with custom enterprise pricing for higher volume.
Pros:
Live in production in an afternoon, with no code changes to ship
Caching pays for itself fast on repetitive or templated prompts
Free tier is generous enough to validate before any spend
Cons:
Attribution is only as good as the tags developers remember to set
It watches spend but cannot stop it, since hard budget caps are absent
The proxy hop adds one more point of failure in the request path
3. Portkey
Best for: teams routing across many models that want budgets, fallbacks and guardrails enforced inside the gateway.
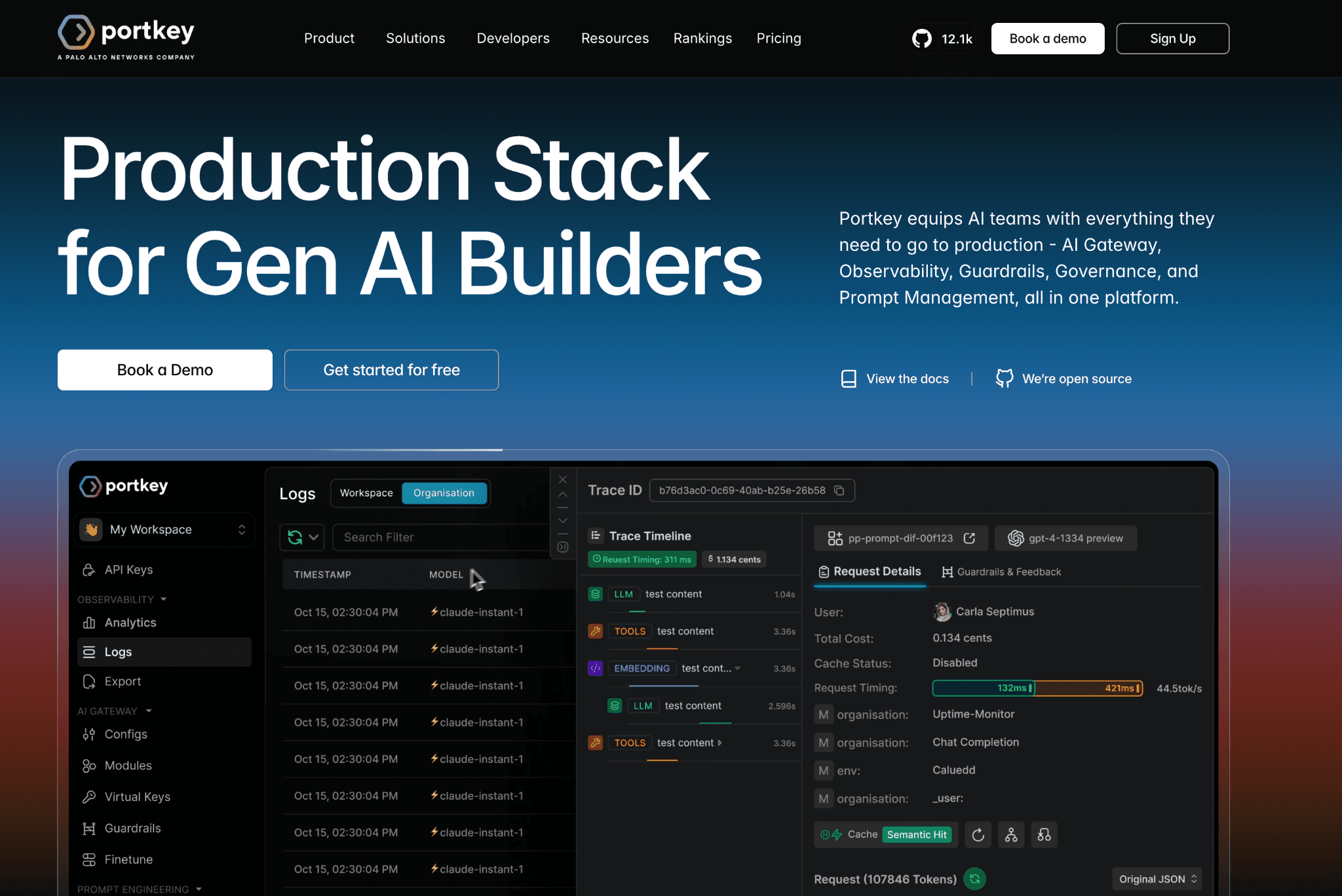
Portkey is an AI gateway that fronts a very large model catalog behind one API, with routing, fallbacks and load balancing built in. Requests flow through it, so it can enforce budgets and guardrails at the edge rather than in each app.
Virtual keys give per-team access control and spend caps and caching reduces duplicate calls. The cost view centers on gateway traffic, so pairing it with a finance-side tool helps when you need full chargeback.
Key features:
Unified API across 1,600+ models
Smart routing, fallbacks and load balancing
Per-key and per-team budget limits
Guardrails for PII and content checks
Semantic and simple caching
Virtual keys for access control
Cost and latency observability dashboards
Open-source (Apache 2.0) self-hostable core
Pricing: The open-source gateway is free to self-host. Managed plans start with a free 10,000-request tier, move to about $49 per month for production, then custom enterprise.
Pros:
Automatic failover keeps apps running when one provider degrades
Spend caps and guardrails apply centrally, not re-coded in every service
Self-hosting the open-source core avoids vendor lock-in
Cons:
Every call depends on the gateway staying healthy
Reporting stops at gateway traffic, short of finance chargeback
The breadth of features is a learning curve for a small team
4. LiteLLM
Best for: engineering teams that want one open-source proxy to standardize many provider APIs and keep data in house.
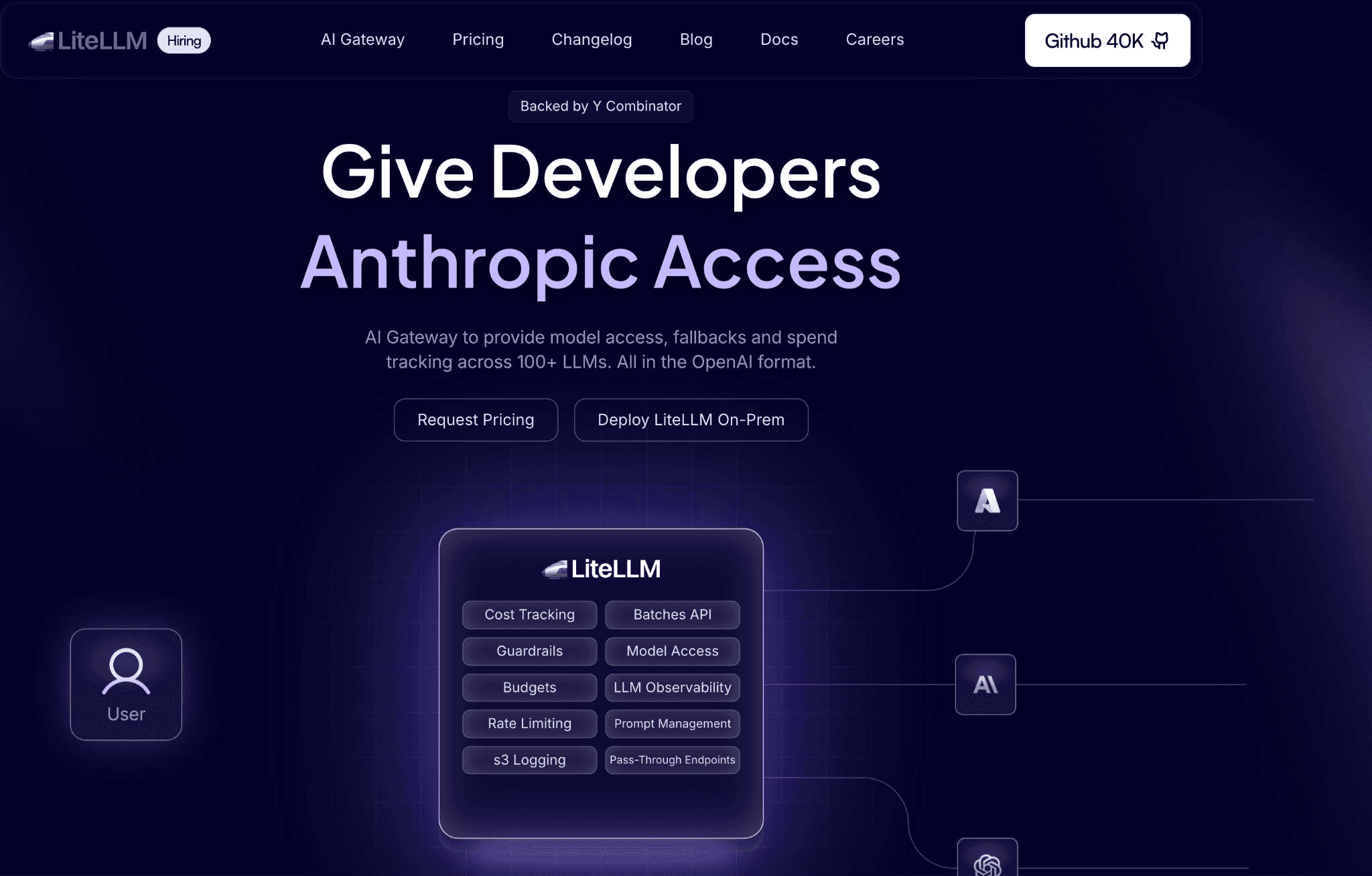
LiteLLM translates calls across 100+ providers into an OpenAI-compatible format, so application code stops carrying per-vendor SDKs. Teams self-host the proxy and own routing, spend tracking and access control in their own environment.
It is a common backbone under other tools because it is flexible and free and routing across providers makes an LLM cost comparison easy to act on. Spend tracking works at the key and team level, though the budget hierarchy is simpler than a dedicated finance platform and Python throughput needs tuning at scale.
Key features:
OpenAI-compatible format across 100+ providers
Self-hosted proxy server for full data control
Spend tracking per key, team and model
Budget and rate limits on virtual keys
Fallbacks and retries across providers
Logging hooks into tools like Langfuse and Datadog
Caching support to reduce duplicate calls
Open-source with an enterprise tier for SSO and support
Pricing: The proxy is free and open-source to self-host with no usage fee. A paid enterprise tier adds SSO, support and governance for larger teams.
Pros:
Ends per-vendor SDK sprawl behind one consistent endpoint
Free and self-hosted, so request data never leaves your environment
Slots in as the routing layer underneath heavier observability tools
Cons:
Spend tracking lacks the deep budget hierarchy of a finance platform
The Python proxy needs tuning to hold up under high request rates
SSO, support and governance sit behind the paid enterprise tier
5. Langfuse
Best for: teams that want the deepest trace-level view of why a request cost what it did, with full control of their data.

Langfuse instruments your code to capture traces and spans, then attaches token counts and cost to each step. That depth helps debug prompts that quietly inflate token use, like a feature stuffing full chat history into every call.
It also handles prompt versioning and evaluations, so it doubles as a quality tool. The trade-off is integration effort, since tracing means adding SDK calls rather than flipping a proxy.
Key features:
Trace and span-level capture of every LLM call
Automatic token and cost tracking per trace
Prompt management and versioning
Evaluations with LLM-as-judge and human annotation
Datasets for regression testing
OpenTelemetry and broad SDK integrations
Dashboards for cost and usage by user or feature
Self-hostable MIT core
Pricing: A free cloud tier covers 50,000 units per month. Paid plans start near $29 per month, with enterprise from about $2,499. The MIT core self-hosts at infrastructure cost.
Pros:
Pinpoints the exact step inflating a prompt, which a proxy cannot see
MIT core allows unlimited self-hosted logging at infrastructure cost
Cost, evals and prompt versioning live in one tool instead of three
Cons:
Instrumenting code is a bigger lift than swapping a base URL
Output is engineering-facing, with no finance chargeback view
Managed cloud cost rises with span volume at scale
6. Datadog LLM Observability
Best for: teams already standardized on Datadog that want LLM token cost in the same pane as their infrastructure telemetry.
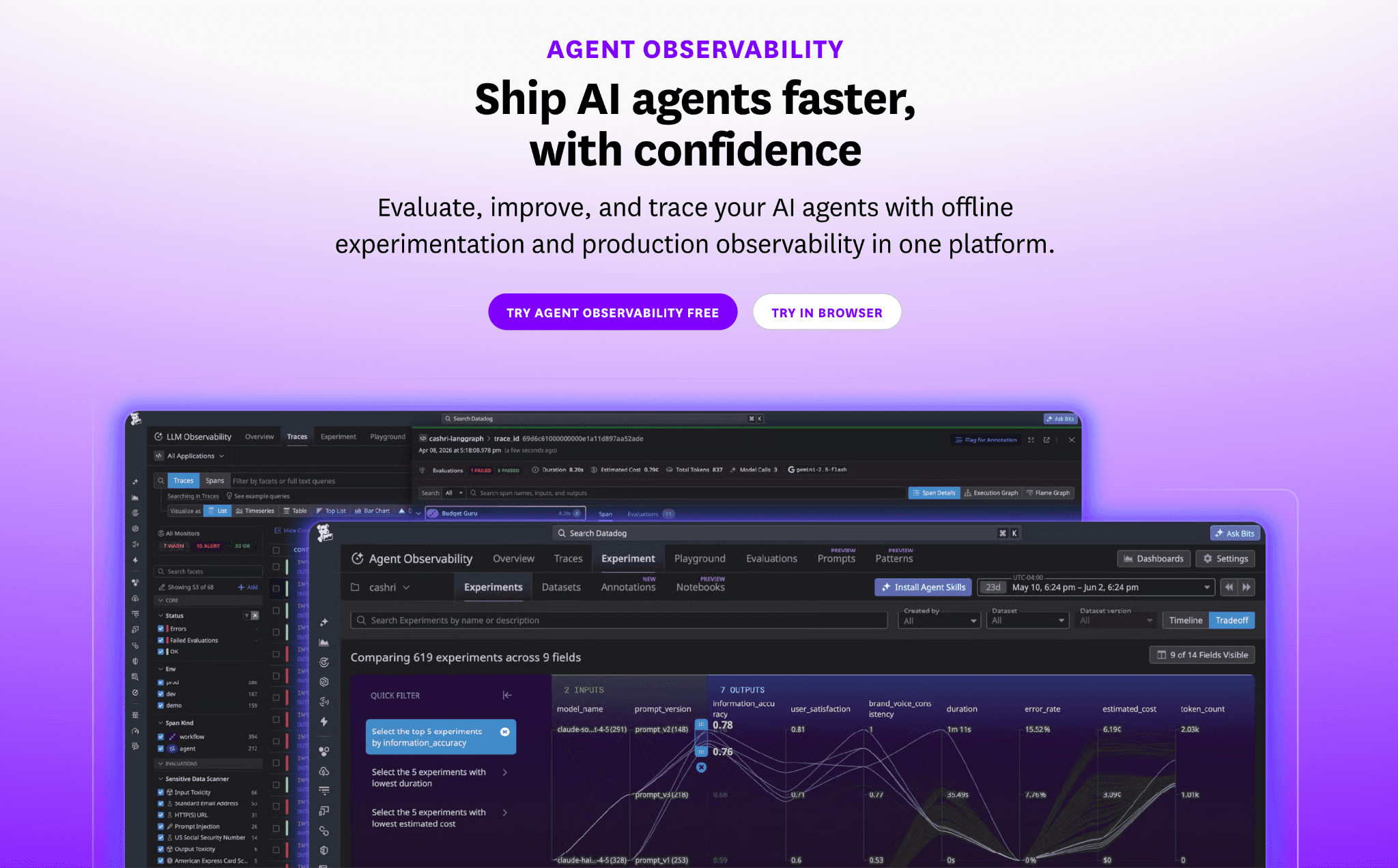
Datadog LLM Observability extends Datadog APM with per-request cost estimation across a wide model set, broken down at the application, trace and span level. It links to Datadog Cloud Cost Management so LLM spend sits next to infrastructure spend.
For a Datadog shop, that means little new tooling to learn. Its estimates lean on published rates like OpenAI API pricing, so for everyone else the value depends on buying into the wider platform and usage-based billing can climb with volume.
Key features:
Per-request cost estimation across 800+ models
End-to-end trace and span breakdown
Tie-in to Datadog APM and Cloud Cost Management
Quality and safety evaluations such as hallucination checks
Prompt and response clustering
Anomaly and error monitoring on LLM calls
Alerting and dashboards inside existing Datadog
PII scanning on prompts and responses
Pricing: Sold as a usage-based add-on to Datadog, billed by indexed LLM spans or requests. The economics work best when Datadog is already your system of record.
Pros:
LLM cost sits beside infrastructure cost in a pane teams already know
Inherits mature alerting, RBAC and APM with nothing new to learn
No extra vendor to procure if Datadog is already in place
Cons:
Hard to justify unless you already pay for Datadog
Per-span billing can spike as request volume grows
Cost figures are estimates, not exact provider-invoice numbers
7. Arize Phoenix
Best for: open-source teams instrumenting agent workflows with OpenTelemetry that want tracing and evaluation together.
Phoenix is an open-source observability tool that captures agent workflows through native OpenTelemetry, so it drops into existing pipelines without a proprietary agent. Token cost rides along with each captured span.
It leans toward experimentation, evaluation and ML-grade analysis like embedding drift, which suits data science teams. Budgets and chargeback are not its job, so finance teams will pair it with something higher up.
Key features:
OpenTelemetry-native tracing via OpenInference
Span-level token and cost capture
Evaluations and experiment tracking
Embedding and drift analysis
Prompt playground for iteration
Framework integrations with LangChain and LlamaIndex
Dataset curation from captured traces
Open-source and self-hostable
Pricing: Phoenix is open-source and free to self-host. The managed Arize AX platform starts around $50 per month, with custom enterprise pricing.
Pros:
Pure OpenTelemetry fits existing pipelines with no proprietary agent
Free to self-host with no seat limits
Strongest evaluation and drift analysis for data science teams
Cons:
No budgets, alerts or chargeback, so it is not a governance tool
Cost data is a side effect of tracing, not a first-class report
Works best paired with a finance-side tool, not on its own
8. TrueFoundry
Best for: regulated enterprises that need a governed LLM gateway running inside their own VPC with strict access control.
TrueFoundry runs an LLM gateway across providers with low routing overhead and strong governance. Token-based rate limits, budgets and role-based access let platform teams control how internal teams consume models.
It self-hosts in your VPC or Kubernetes, which fits compliance-heavy environments. As a gateway and broader MLOps platform, its cost picture centers on the request path rather than the finance-owned view you get from AI agent tools for FinOps.
Key features:
LLM gateway across multiple providers
Low routing overhead at scale
Token-based rate limits and budgets per team
Role-based access control and virtual keys
Guardrails and PII redaction
Cost and latency observability metrics
Self-hosted in your own VPC or Kubernetes
Model catalog and deployment as part of a wider platform
Pricing: Pricing is usage-based on gateway throughput with a free trial, plus custom enterprise plans for self-hosted deployments.
Pros:
Runs entirely in your VPC, which clears security and compliance reviews
One platform covers the gateway plus model deployment
RBAC and PII redaction meet the bar for regulated teams
Cons:
Heavier to stand up than a hosted drop-in proxy
Cost view is gateway-centric, not a finance-led report
Broader MLOps scope is more than a team needing only token tracking
How to Choose the Right AI Token Management Software
You need finance-grade chargeback: Amnic attributes token spend to teams and cost centers and enforces budgets before the invoice.
You want fast request-level visibility: Helicone gives per-call cost with a one-line proxy.
You route across many models: Portkey or LiteLLM put budgets and normalization in the request path.
You debug prompt and agent behavior: Langfuse or Arize Phoenix give trace-level detail.
You already run Datadog: Datadog LLM Observability keeps token cost in the same telemetry.
You run a regulated platform: TrueFoundry adds in-VPC governance and access control.
Match the tool to the job, then size the spend you are about to govern before you commit.
Common Mistakes When Choosing a Token Management Tool
Treating logging as governance: A proxy that logs every call still does not cap spend. If you cannot set a budget per team or model, you are reading the meter, not controlling it.
Ignoring reasoning tokens: Reasoning tokens are billed as output but never appear in the response, so length-based estimates undercount cost. Pick a tool that reads the usage object directly.
Stranding token data in engineering: When token spend never reaches finance, no one reconciles it against budget. Tie it to the same practice that governs chargeback vs showback across the business.
Buying per-model instead of per-question: The real question is who spent what and why. A tool that only splits by model cannot answer it.
Why Teams Choose Amnic for AI Token Management
Amnic is built around attribution, control and altitude. It assigns input and output tokens to teams and cost centers, enforces budgets before the bill lands and keeps token spend in the same platform that runs FinOps for AI. That is the gap most token tools leave open, since they report to engineers, not finance.
The outcomes are real. Open Financial cut overall cloud cost by 30%, Jiffy.ai lowered Kubernetes cluster cost by 50% through rightsizing and MetaMap reduced EC2 cost by 33% on the platform. As Ajeesh Achuthan, Co-Founder and CTO of Open Financial, put it, "Using Amnic has been nothing short of transformational," with the platform analyzing cost "at a depth that would take us several hours, if not days."
Teams that want one system for both AI and cloud get token governance and natural-language reporting in the same place, instead of stitching a proxy to a separate finance tool.
To see token attribution against your own OpenAI, Anthropic, Gemini and Bedrock usage, request a demo.
Frequently Asked Questions
What are AI token management tools?
They are tools that track, attribute and govern the input, output and reasoning tokens your applications send to model providers. They convert raw token counts into cost you can assign to a team, feature or customer and let you set budgets to cap that spend before it reaches the invoice.
Why is a provider dashboard not enough?
A provider dashboard shows total spend but not which feature, user or model drove it. Once you run several models or agents, it cannot attribute cost or alert on the right spikes, so teams add a dedicated tool that tags and budgets spend at the request level.
What is the difference between a gateway and an observability tool?
A gateway sits in the request path as a proxy and logs usage as traffic flows through. An observability tool instruments your code to capture detailed traces and spans. Gateways are lighter to deploy, while tracers give deeper per-step visibility into why a call cost what it did.
Do these tools track reasoning tokens?
The stronger ones read the usage object in each API response, which reports reasoning tokens where the model exposes them. Reasoning tokens are billed as output but stay invisible in the text, so reading the usage object is the only accurate way to count them.
Can AI token management connect to cloud FinOps?
Yes. Platforms like Amnic attribute token spend to teams and cost centers inside the same system used for cloud cost, so finance reconciles AI and cloud spend together. That avoids two separate dashboards that never line up at month end.
Are there free AI token management tools?
Yes. LiteLLM and Arize Phoenix are open-source and free to self-host and Helicone, Portkey and Langfuse offer free tiers with monthly request or unit caps before paid plans begin. Finance-grade governance usually starts on a paid or usage-based plan.
Govern Your Token Spend Before the Next Invoice
A provider dashboard tells you what you spent, not who spent it or why. Amnic attributes every token to a team and cost center, enforces budgets before the invoice and turns the data into reporting any stakeholder can read through the Amnic AI agents. Start the one-month trial to see it against your own usage.
Better visibility and management into AI Tokens?
Start with a 30 day trial
Connect leading LLMs
24 hour time to value
Stay ahead of AI Spend

Make AI spend visible, controllable, and accountable.
Gain insights into your AI token costs at a team, customer, business unit and individual user level to measure and manage AI utilization.
Recommended Articles

8 Best Llama Cost Management Tools in 2026
Read More

8 Best Amazon Bedrock Cost Optimization Tools for 2026
Read More

7 Best Amazon Bedrock Cost Monitoring Tools
Read More

8 Best Gemini Cost Visibility Tools for 2026
Read More

7 Best Multimodal Cost Optimization Tools for 2026
Read More

5 Best Anthropic Cost Allocation Tools for 2026
Read More






