GCP CUD vs. SUD: How to Choose the Right Discount Strategy
12 min read
Comparisons
Discounts and commitments
GCP

Table of Contents
GCP CUD vs. SUD: How to Choose the Right Discount Strategy
Cloud costs don’t usually break because of one big decision. They grow because of a hundred small ones, an extra region here, a larger machine type there, a workload that never got rightsized. Then AI enters the picture, usage patterns shift, and what used to feel elastic starts feeling expensive.
If you’re running workloads on Google Cloud Platform (GCP), two of the most powerful cost-optimization levers available to you are:
Committed Use Discounts (CUDs)
Sustained Use Discounts (SUDs)
Both can significantly reduce compute spend, but they operate in fundamentally different ways. One rewards long-term commitment and predictability. The other rewards consistent usage without requiring a contract. Choosing the wrong model, or failing to intentionally combine them, can mean leaving 20-70% in savings on the table.
In this blog, we’ll go beyond surface-level definitions and explore:
How CUDs and SUDs actually work under the hood
Where each model creates the most financial leverage
Real-world workload scenarios and decision frameworks
Common (and costly) mistakes teams make
The latest trends shaping cloud discount strategy in 2026
Whether you're a FinOps lead, cloud architect, or CFO evaluating long-term commitments, this breakdown will help you align discount strategy with workload behavior and turn cloud pricing into a strategic advantage.
Understanding GCP’s Discount Models
What are Committed Use Discounts (CUDs)?
Committed Use Discounts (CUDs) are GCP’s way of rewarding predictability. In exchange for committing to a defined level of usage or spend for 1 or 3 years, you receive significantly reduced pricing compared to on-demand rates.
But this isn’t just a “discount purchase.” It’s a financial commitment. You’re essentially telling Google Cloud:
“I know I will use at least this much compute capacity consistently for the next 12-36 months.”
In return, GCP lowers your effective rate, often substantially.
There are two primary types of CUDs, and the distinction matters.
Resource-based CUDs
With resource-based CUDs, you commit to a specific quantity of infrastructure resources, such as:
vCPUs
Memory
GPUs
Local SSDs
These commitments are typically tied to a region, meaning alignment between your deployments and commitment location is critical.
How they work in practice:
You purchase a fixed hourly commitment (e.g., 200 vCPUs in us-central1).
Any eligible usage up to that amount receives the discounted rate.
If you exceed the commitment, additional usage is billed at standard on-demand pricing.
If you underutilize it, you still pay for the committed amount.
Best suited for:
Stable, always-on production workloads
Backend services with consistent capacity requirements
Long-running clusters with minimal fluctuation
Because these are highly specific, they typically offer the deepest discounts, up to ~70% depending on term length and resource type.
The tradeoff? Less flexibility. If your architecture changes or shifts regions, your commitment may no longer fully apply.
Spend-based (flexible) CUDs
Spend-based CUDs take a different approach.
Instead of committing to specific machine types or resource quantities, you commit to a minimum hourly spend across eligible services at the billing account level.
This model is more abstract, and more flexible.
How they work:
You commit to spending, for example, $X per hour on eligible compute services.
Any qualifying usage counts toward fulfilling that commitment.
Discounts are applied automatically to matching services.
Eligible services often include:
Compute Engine
Google Kubernetes Engine (GKE)
Cloud Run
Best suited for:
Organizations with diversified workloads
Teams running mixed services
Environments where machine types frequently change
Containerized or platform-driven architectures
Discounts are generally slightly lower than highly targeted resource-based CUDs, but the flexibility often makes up for it.
In modern, dynamic environments, spend-based CUDs have become increasingly popular because they reduce the risk of architectural lock-in while still delivering strong savings.
Also read: Running predictable and cost-optimized workloads on GKE
What are Sustained Use Discounts (SUDs)?
Sustained Use Discounts (SUDs) are automatic usage-based rewards. No contracts. No upfront purchases. No forecasting required.
If you run eligible Compute Engine instances consistently throughout a billing month, GCP gradually applies increasing discounts based on how long they run.
How SUDs work:
Once usage exceeds roughly 25% of the billing month, discounts begin to apply.
The longer the VM runs, the larger the discount.
If an instance runs for the entire month, savings can reach up to ~30%.
Discounts are calculated automatically and credited at the end of the billing cycle.
There’s nothing to purchase. Nothing to configure. It simply happens.
Why SUDs matter
SUDs reward consistency, but without commitment risk.
They are especially valuable when:
You have workloads that run frequently but not predictably enough for long-term commitments.
You're early in a cloud migration and still observing usage patterns.
Teams spin up resources dynamically but tend to leave them running for extended periods.
You want baseline savings without financial lock-in.
However, SUDs don’t match the depth of savings offered by CUDs. They are a passive optimization mechanism, not a strategic one.
Also read: AWS Savings Plans vs Reserved Instances: Choosing the Right Commitment for Your Cloud Costs
Committed Use Discounts vs. SUD
Criteria | Committed Use Discounts (CUDs) | Sustained Use Discounts (SUDs) |
Commitment Required | Yes, 1 or 3 year contractual commitment | No commitment required |
Setup Needed | Manual purchase and capacity planning required | Automatic, no action needed |
Discount Depth | Higher, can reach up to ~70% depending on resource and term | Moderate, up to ~30% for full-month usage |
How Savings are Triggered | Based on purchased commitment coverage | Based on actual monthly usage duration |
Flexibility | Lower. Tied to region, resource type, or spend scope | High. Adjusts naturally to usage patterns |
Financial Risk | Risk of over-commitment if usage drops | No downside risk |
Forecasting Required | Yes, historical usage analysis strongly recommended | No forecasting needed |
Budget Predictability | Very high, known committed spend | Medium, depends on actual usage each month |
Best For | Stable, always-on production workloads with predictable baselines | Consistent but variable workloads or early-stage cloud environments |
Strategic Role | Proactive cost optimization lever | Passive, automatic cost optimization mechanism |
Bottom Line
CUDs maximize savings when you have confidence in your baseline usage.
SUDs provide effortless savings when flexibility matters more than commitment.
For most mature environments, the strongest strategy combines both, covering stable baseline workloads with CUDs while allowing variable usage to benefit from SUD automatically.
How CUD and SUD Discounts are Applied in Practice
How Committed Use Discounts are applied
When you purchase a CUD:
The discount applies first to matching eligible usage.
If you exceed your committed amount, excess usage is billed at standard rates (and may qualify for SUD).
If you underutilize your commitment, you still pay for the committed amount.
This means forecasting matters. Overcommitting leads to wasted spend.
Spend-based CUDs are applied at the billing account level and can span multiple services, making them more flexible than older, resource-bound models.
How Sustained Use Discounts are applied
SUDs are calculated automatically based on:
VM uptime percentage during the billing month
Aggregated usage across instances of the same machine type within a region
Credits are applied at the end of the month.
There’s no risk of underutilization, but there’s also no guarantee of maximum savings unless workloads run consistently.
When to Use CUDs vs. SUDs
Use Committed Use Discounts when… | Use Sustained Use Discounts when… |
Workloads run 24×7 with stable capacity | Workloads fluctuate significantly |
Infrastructure baseline is predictable | Usage patterns are still stabilizing |
You have 3-6+ months of consistent usage data | You’re early in the migration or experimentation phase |
Budget certainty is a priority | You want zero commitment risk |
You can clearly define a stable baseline | You need maximum flexibility |
Example: Always-on backend service cluster | Example: Dev, staging, CI/CD, batch, or burst environments |
Ask yourself the following questions when choosing between GCP CUD Vs SUD:
Is my workload predictable for the next 12-36 months?
Do I have historical usage data?
Can I isolate a stable baseline?
How much risk tolerance do I have for underutilization?
If stability is high → Lean toward CUD.
If variability is high → Let SUD handle it.
If mixed → Combine both.
The smart strategy could also be to use both…
Many mature organizations combine them:
Start with SUDs while analyzing usage.
Once stable patterns emerge, layer in CUDs.
Leave burst capacity uncovered so it can flex without commitment.
This hybrid approach balances flexibility with maximum savings.
Real-World Scenarios for CUD Vs. SUD
Scenario 1: Mature production workload
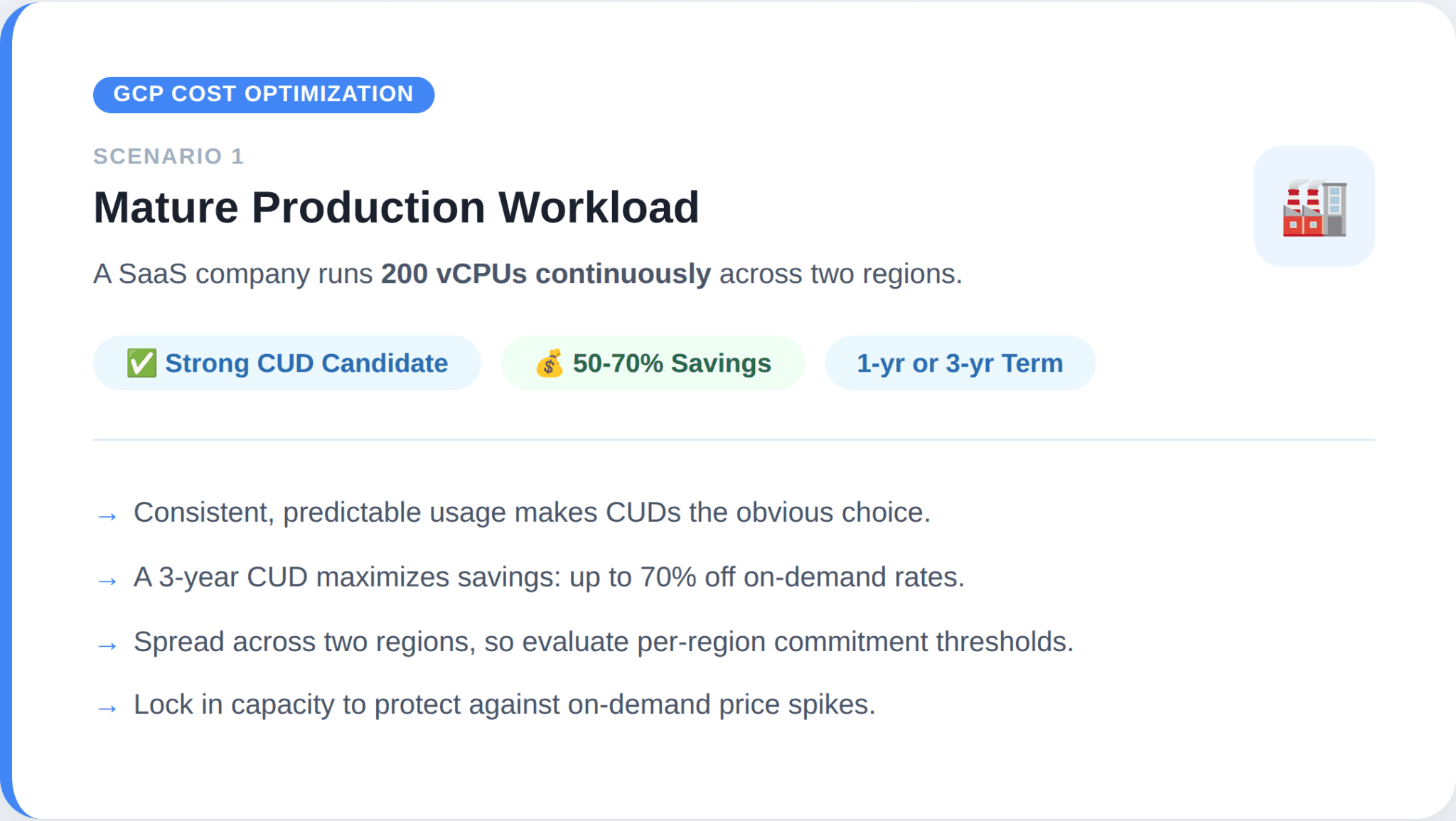
Scenario 2: Spiky batch processing

Scenario 3: Hybrid environment
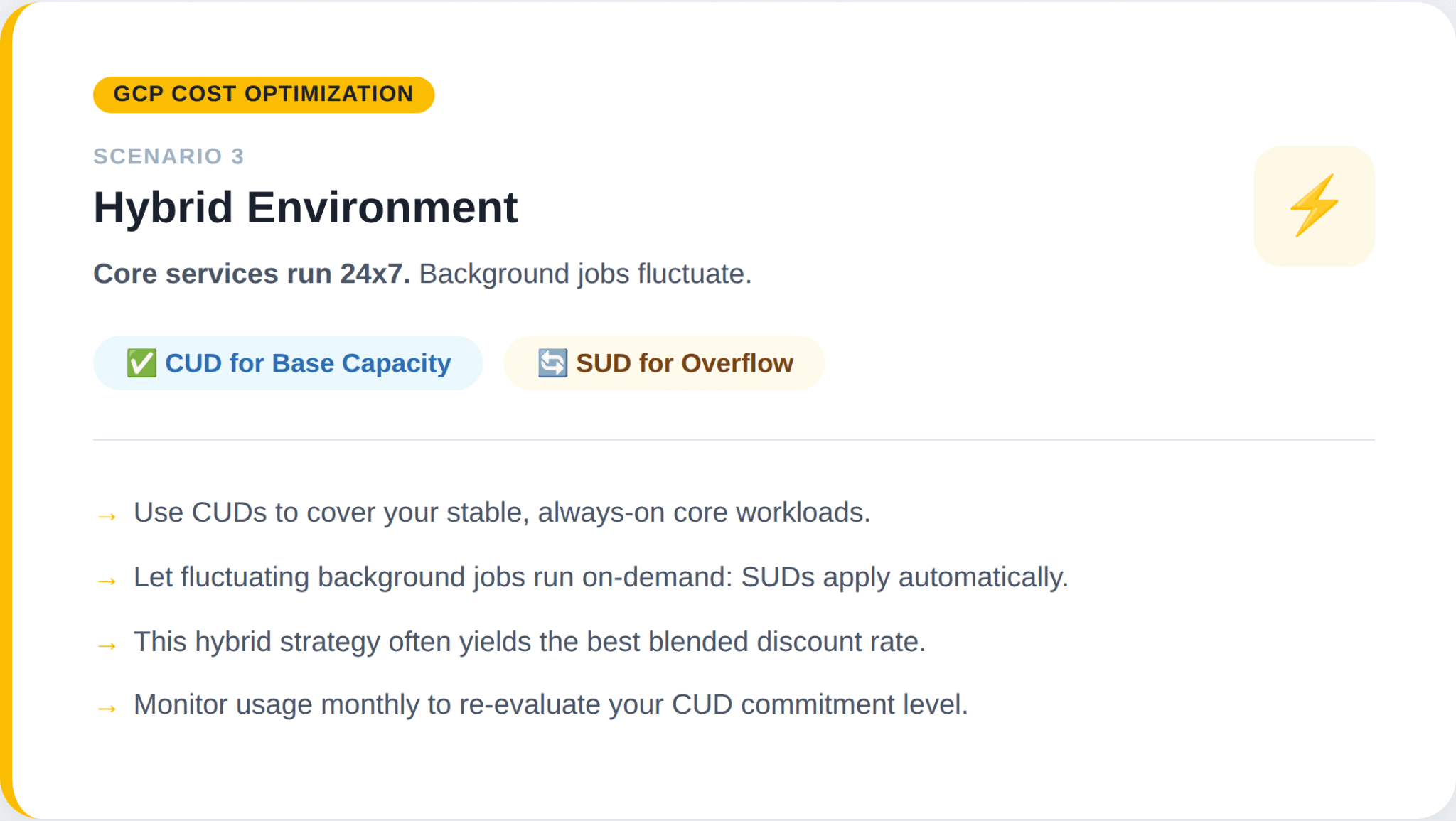
Common Mistakes to Avoid
Overcommitting too early
One of the most expensive mistakes teams make is purchasing large CUDs before their workloads have stabilized.
It’s tempting to lock in maximum savings as soon as you see consistent usage. But early cloud environments, especially during migrations, refactoring, or AI experimentation, are volatile. Architectures change. Regions shift. Instance types get rightsized.
If you commit too aggressively:
You may end up paying for unused capacity.
Your effective discount shrinks.
Savings turn into sunk costs.
Best practice: Observe at least 3-6 months of stable usage patterns before committing large volumes. Start conservative and scale commitments gradually.
Ignoring regional scope
Many CUDs, particularly resource-based ones, are region-specific.
If you purchase commitments in one region but later:
Expand into another region
Migrate workloads
Implement multi-region redundancy
Your commitment may no longer fully apply.
The result is that you’re paying for committed capacity in Region A while running workloads in Region B at on-demand pricing.
Best practice: Align commitments with long-term architectural strategy, not just current deployment state.
Not monitoring coverage
Buying CUDs is not the end of optimization, it’s the beginning.
Many teams:
Purchase commitments
Assume they’re saving money
Never verify actual coverage percentage
Without tracking:
You may be under-covered (leaving savings on the table)
Or over-covered (wasting committed spend)
Coverage ratios should be monitored continuously, ideally as part of your FinOps reporting cadence.
Best practice: Track the following-
Commitment coverage %
Utilization %
On-demand spillover
Unused commitment hours
Treating discounts as a one-time decision
Workloads evolve:
AI inference traffic grows.
Data pipelines expand.
Services get containerized.
Teams adopt new regions.
But many organizations treat CUD decisions as annual exercises. That’s risky.
A commitment that made sense 12 months ago may no longer reflect current architecture. Conversely, stable workloads may now justify deeper commitments.
Best practice: Review discount strategy quarterly alongside:
Infrastructure growth
Cost trends
Rightsizing initiatives
Business projections
Current Trends in GCP Discount Strategy (2026)
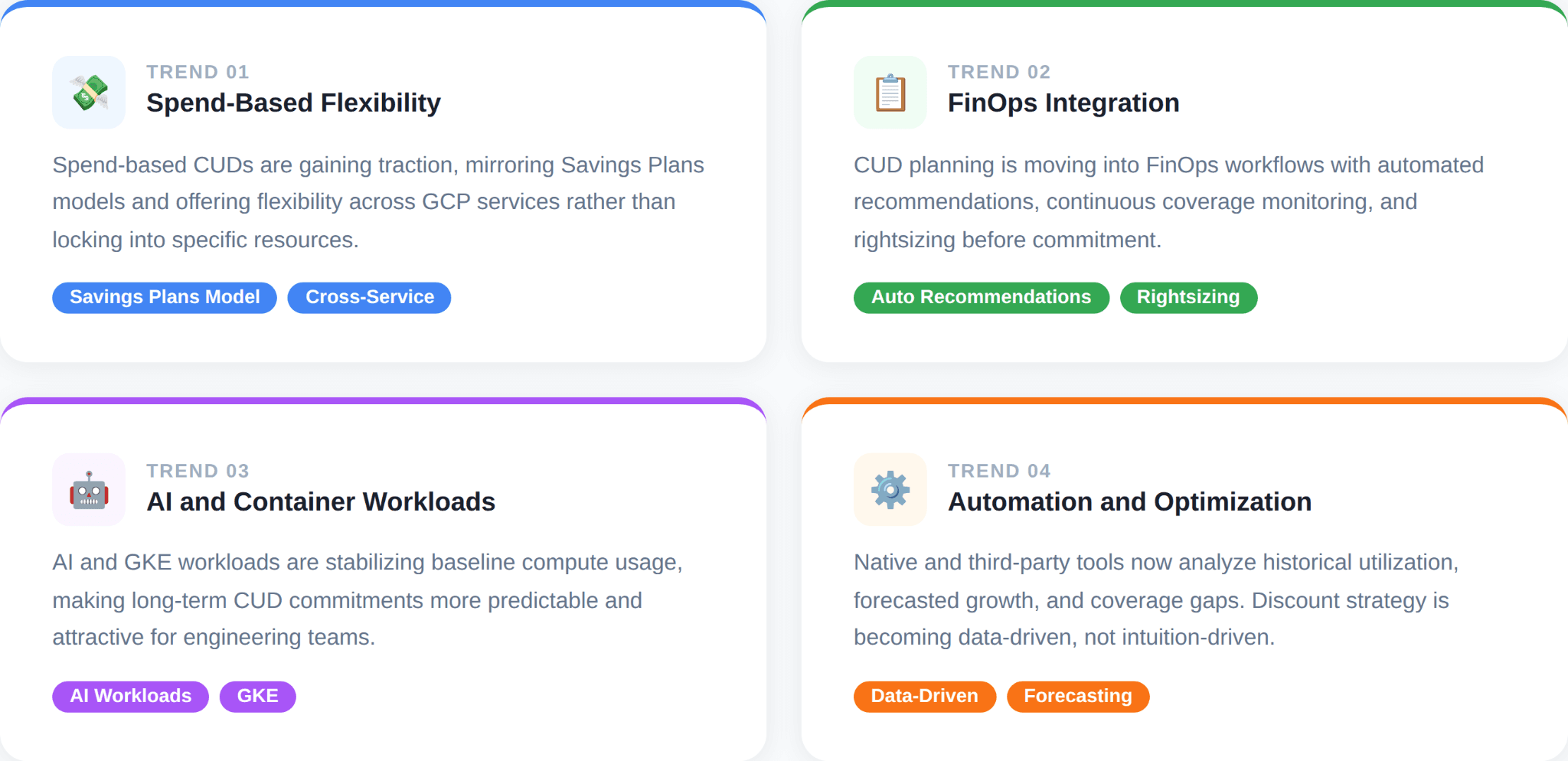
Shift toward spend-based flexibility
Organizations are moving away from highly granular, resource-locked commitments and toward spend-based CUDs that offer cross-service flexibility.
Why this matters:
Modern architectures are no longer static VM fleets, they span Compute Engine, GKE, Cloud Run, and managed services.
Engineering teams want architectural freedom without invalidating long-term commitments.
Finance teams want predictable savings without micromanaging instance families.
Spend-based CUDs behave more like financial instruments than infrastructure reservations. Instead of betting on a specific machine type in a specific region, companies commit to a dollar baseline, aligning commitments with budget forecasts rather than infrastructure minutiae.
Result: Discount strategies are increasingly tied to financial modeling, not just capacity planning.
FinOps integration
Discount management is no longer a one-time infrastructure decision, it’s embedded in FinOps operating models.
Modern organizations are:
Using automated recommendation engines to size commitments
Tracking real-time CUD coverage ratios
Running quarterly commitment reviews alongside budget cycles
Rightsizing workloads before purchasing commitments
In mature environments, CUD coverage is treated as a KPI:
% of eligible spend covered
Effective blended discount rate
Commitment utilization efficiency
This represents a major shift: Discount strategy is now a continuous optimization loop, not a procurement event.
AI & container workloads increasing baselines
AI training jobs, inference services, and container orchestration platforms (like GKE) are reshaping workload patterns.
Historically:
Many workloads were bursty or migration-phase unstable.
Teams hesitated to commit long-term.
Now:
AI inference services often run 24×7.
Platform teams maintain steady baseline clusters for Kubernetes.
Microservices architectures create persistent compute floors.
Even if applications scale dynamically, there’s usually a stable baseline layer that runs continuously.
This makes hybrid strategies more common:
Commit the predictable base layer with CUDs.
Let scaling layers benefit from SUDs or on-demand pricing.
AI isn’t just increasing spend, it’s increasing predictable spend.
Automation & optimization tools
Manual spreadsheet forecasting is fading.
Organizations now rely on:
Native GCP recommendations
Third-party FinOps platforms
Custom forecasting models using historical billing export data
These tools analyze:
6-12 months of historical utilization
Seasonal patterns
Growth trends
Regional distribution
Under- or over-commitment gaps
The outcome is a data-backed commitment plan that answers:
What portion of my compute should be committed?
For how long?
In which regions?
At what risk tolerance?
Discount strategy has evolved from intuition (“this cluster looks stable”) to statistical modeling (“95% confidence this baseline persists for 18 months”).
Final Thoughts
The key takeaway from this blog was:
CUDs reward certainty and planning.
SUDs reward consistency without commitment.
The best strategy evolves with your architecture.
There’s definitely a lesson to learn that cloud cost optimization should be continuous and not occasional. Monitoring usage, reviewing commitments, and adapting as workloads evolve is what separates reactive cost control from strategic cost management.
If your organization hasn’t revisited its CUD and SUD coverage recently, now might be the right time.
[Request a demo and speak to our team]
[Sign up for a no-cost 30-day trial]
[Check out our free resources on FinOps]
[Try Amnic AI Agents today]
Frequently Asked Questions
1. What is the main difference between CUD and SUD in GCP?
Committed Use Discounts (CUDs) require you to commit to a specific level of usage (or spend) over 1-3 years in exchange for deeper discounts. Sustained Use Discounts (SUDs) apply automatically when you use eligible resources consistently within a billing month, no commitment required.
2. When should I choose CUD over SUD?
Choose CUD when you have predictable, steady baseline usage, such as 24×7 production workloads, AI inference services, or stable Kubernetes clusters. CUDs deliver higher savings when you’re confident usage will persist.
3. When is SUD a better option than CUD?
SUD is better for variable or spiky workloads, like batch jobs, development environments, seasonal traffic, or experimentation.
It offers flexibility without long-term commitment, though savings are typically lower than CUD.
4. Can I use CUD and SUD together?
Yes. Many organizations use a hybrid strategy:
Cover predictable baseline usage with CUDs
Allow burst or variable workloads to benefit from SUD or on-demand pricing
This balances maximum savings with operational flexibility.
5. What happens if I overcommit with CUD?
If your usage drops below your committed level, you still pay for the full commitment term. That’s why forecasting, rightsizing, and monitoring commitment coverage are critical before purchasing CUDs.
Recommended Articles
8 FinOps Tools for Cloud Cost Budgeting and Forecasting in 2026
5 FinOps Tools for Cost Allocation and Unit Economics [2026 Updated]
Read Our Breaking Bill Edition
Better visibility and management into AI Tokens?
Start with a 30 day trial
Connect leading LLMs
24 hour time to value
Stay ahead of AI Spend

Make AI spend visible, controllable, and accountable.
Gain insights into your AI token costs at a team, customer, business unit and individual user level to measure and manage AI utilization.
Recommended Articles

Compare Input vs Output Token Pricing: Why Output Costs More and How to Budget for It
Read More

Vertex AI vs Bedrock: The Enterprise Platform Decision That Outlives the Token Price
Read More

Gemini vs GPT: Which AI Model Fits Your Workflow and Budget
Read More

H100 vs A100: Specs, Cost and Which GPU Wins for Your Workload
Read More

OpenCost vs Kubecost: Key Differences and How to Choose
Read More

6 Best Datadog Alternatives for Cloud Cost Management in 2026
Read More






