The Great Token Panic and the Birth of Tokenomics
10 min read
FinOps

Table of Contents
Every technology wave invents a scorecard before it understands itself.
The web era counted page views. Nobody knew how to value a website, so we agreed on the easiest thing to measure, and spent a decade building bot farms and ad models on top of it. The app era counted downloads. Neither number ever told you whether a business was actually good. They just told you it was busy.
The AI era picked tokens. And for about six months, that felt fine. Then the bills landed, and the entire industry walked into FinOps X 2026 in San Diego carrying the same bruise.
Day 1's keynote from J.R. Storment, Executive Director of the FinOps Foundation, named the problem and, more importantly, named the fix: a brand new discipline called tokenomics, backed by a new foundation. Here are the 10 takeaways that matter.
The road to the great token panic
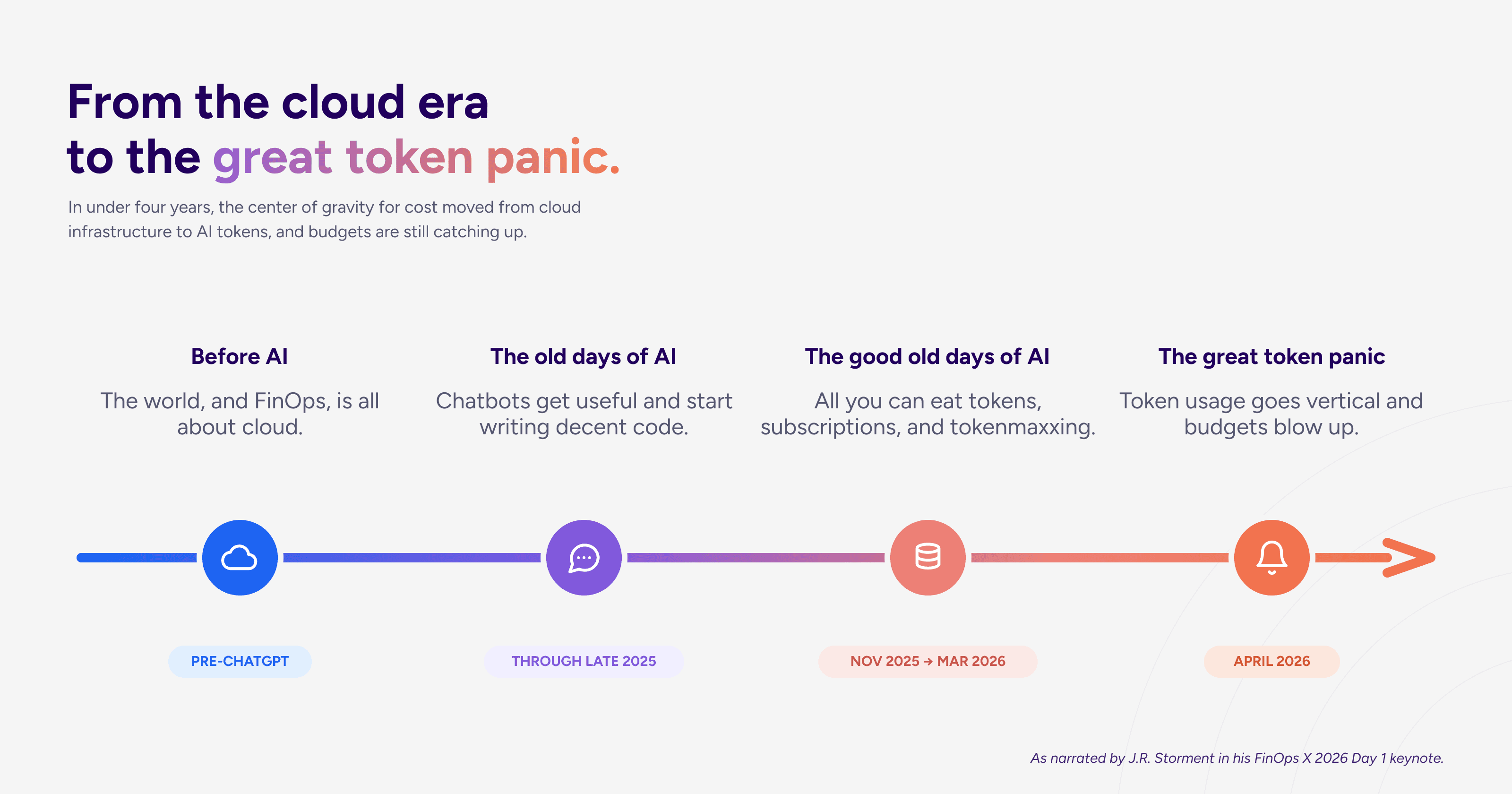
That last stage is where the story really starts. Here are the 10 takeaways from FinOps X 2026 day 1.
1. For six months, "tokenmaxxing" was a sport.
For a stretch from late 2025 into early 2026, AI ran on flat monthly plans and generous limits. So teams did what teams do with an unmetered resource. They went all in.
"Tokenmaxxing" became a thing. Companies built internal leaderboards. Developers bragged about usage like it was a high score. Whoever burned the most tokens was, somehow, winning. One global CIO reportedly told the FinOps Foundation he had unlimited budget for tokens.
You can guess how that ended.
2. Teams burned their annual AI budget by spring.
By spring 2026, the free ride ended. CTOs started saying things out loud like "we blew our budget, and it's only April."
Teams that had carefully modeled their 2026 AI spend, conservative case, aggressive case, everything in between, discovered they'd torn through their full-year budget before summer. The headlines piled up and companies started quietly capping AI usage and hoping their CEOs wouldn't notice.
Uber blew through its entire annual AI budget in roughly four months, its CTO revealed in April, then started capping employees at $1,500 a month per AI coding tool to rein it in. Uber wasn't alone. The pattern got common enough that OpenAI's Sam Altman said a meme was circulating among corporate customers: "The company spent its entire 2026 budget in the first quarter. Can you make it more efficient?"
The FinOps Foundation has a name for this moment. The great token panic.
Here's the trap, though. Most people read the panic as a price problem. It isn't. Token prices fell hard from 2023 through late 2025, then flattened out around November 2025 and have barely moved since. The bill exploded anyway.
Why? Because usage went vertical while price went flat. Two things lit the fuse. Context windows ballooned from thousands of tokens to millions, so every single interaction got heavier. And agents arrived, looping, retrying, and self-correcting around the clock without ever getting tired. A tireless machine hammering an expensive model is a beautiful thing right up until you read the invoice.
So this was never really a cost problem. It's a measurement and allocation problem. The scorecard broke.
3. Token prices are stuck flat until 2028, and usage is heading for 120 quadrillion
If you budgeted on the assumption that per token prices keep falling, it's time to rebuild that model. The plateau is structural, not a pause.
The whole supply chain is jammed. GPUs are scarce. Power is scarce. Even copper, the literal wiring for GPU clusters, is constrained. The neoclouds (CoreWeave, Lambda, Crusoe) are pushing minimum commitments from one year out to three to five years because they can't promise flexibility they don't have.
The four biggest cloud providers are sitting on more than $2 trillion in combined infrastructure backlog. And industry forecasts don't see real relief until 2028.
Translation: cheaper-per-token won't save you. The unit price can sit flat or drift up while your bill keeps climbing, purely on volume. Anyone who anchored their AI ROI math to falling unit costs is now staring at a gap between the forecast and the invoice.
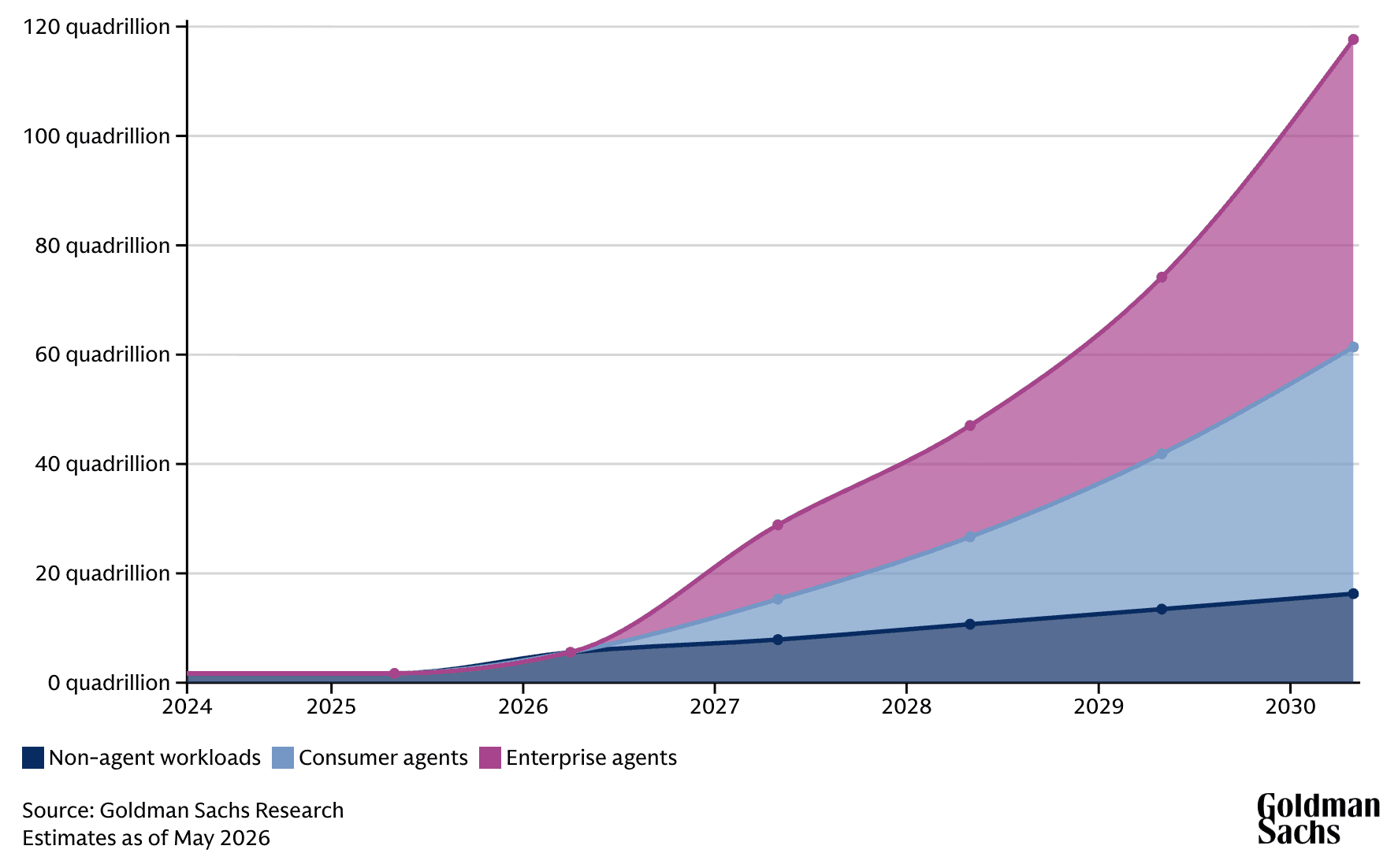
And the scale ahead is hard to even picture. Global token usage sits around 6 quadrillion tokens today.
Goldman Sachs projects 120 quadrillion per month by 2030, a 24x jump in four years, moving faster than cloud adoption ever did. The inference market alone is forecast to grow from roughly $106 billion in 2025 to $255 billion by 2030. This stopped being a line item. It's a budget category.
4. The token charge is one line. The other eight cost layers are invisible.
Here's the uncomfortable truth underneath token pricing: you pay per token, but the token charge is the tip of the iceberg. The token bill is layer one. The other eight sit beneath it, mostly unmetered:
Retrieval and data. The vector databases behind your RAG setup are charged on what you store and query.
Orchestration. Workflow overhead that multiplies fast the moment you run multi-agent systems.
Inference infrastructure. Idle compute you pay for, whether it's working or not.
KV cache. The memory that lets a model "remember" a long conversation, quietly racking up charges that surface as a surprise line item.
Evaluation and monitoring. The tracing and observability that tell you whether your models actually work.
Governance and data residency. Running in a specific region to meet compliance can cost meaningfully more than a default deployment.
Human labor. Prompt engineering, output review, data annotation. Still one of the biggest costs of all.
Waste. The retries, the hallucination rework, and the shadow AI nobody's tracking.
Most teams can see the token bill. Almost nobody has instrumentation on everything underneath it. That blind spot is precisely where the overruns live.
5. Tokenomics, explained: FinOps that starts where the token is made
This is the moment the keynote named the thing. Three words, tokens, token era, token economics, collapse into one: tokenomics.
“Tokenomics is the emerging discipline of turning energy and capital into AI tokens, then consuming them efficiently to drive value.”
FinOps assumes the resources already exist and your job is to procure and optimize them. Tokenomics reaches one step further back, to where tokens get manufactured in the first place, and one step further forward, into the business model itself.
The simplest way to hold it is three buckets:
Production is turning energy, capital, and hardware into token capacity, the data centers, the GPU clusters, and the procurement strategy.
Consumption is the part that feels familiar to any FinOps practitioner: allocation, forecasting, model routing, caching, and the daily optimization grind.
Value is the genuinely new frontier, how you monetize tokens, how AI cost reshapes your product margins, and what it all means for headcount.
That last bucket is the real departure. Cloud cost management never had to ask how the underlying resource gets made, or how it should reprice your product. Tokenomics does.
6. The CFO question changed from "what did we spend" to "what did we get"
Nobody has the perfect metric yet. The candidates floating around the conference, cost per verified outcome, direct allocation percentage, route win rate, cache and batch coverage, are early and unsettled. But the shift in framing is the point. We're moving from counting cost to proving value.
And that's a familiar muscle, not an alien one. As Accenture's Mike Eisenstein reminded the room, practitioners have already scaled cost management across cloud, containers, and serverless. AI is the next layer, not a different planet, as long as teams expand into governing the cost of business outcomes. FinOps, in his framing, doesn't just get a seat at the table. Practitioners help set the agenda.
Or, as Prudential's Pooja Kumar put it from the stage: "Traditional FinOps is now table stakes." The job now is to advance past it.
7. Three AI pricing models, and why opacity is a feature, not a bug
One more thing worth flagging, because it shapes how hard any of this is. AI pricing comes in three flavors, and they get progressively darker.
Credit systems hide almost everything. You often can't tell which model ran, how many tokens it used, or the real per token cost, and a monthly credit pool can vanish in a 15 minute burst.
Hybrid models layer token rates on top of credits, and the abstractions stack up rather than simplify.
Direct, bring your own key access gives you full telemetry and published rates, but demands real operational overhead.
The pattern is clear. Opacity is a feature for the provider. They get pricing flexibility when you can't see clearly. The only durable defense is instrumentation: log every call, track every model, and build your own source of truth instead of trusting the dashboard you're handed.
8. The same token costs different amounts on every cloud.
Here's the part that should land for anyone running cost intelligence across more than one provider.
Tokens now flow through the same multi-cloud sprawl your existing spend already does. The same token from the same model shows up priced differently depending on whether you bought it through one hyperscaler's marketplace, another's bundled credit system, or a direct key.
Comparing apples to apples across AWS, Azure, and GCP, plus the model providers stacked on top, is exactly the problem cost intelligence platforms were built to solve. Tokenomics is that discipline extending into AI, not replacing what came before.
This is why the formalization matters. The Linux Foundation announced the intent to launch the Tokenomics Foundation, a neutral, open body for standards, benchmarks, and best practices on the economics of AI infrastructure, working hand in hand with the FinOps Foundation. It'll build open specifications, set cross-provider benchmarks, create certifications for AI-focused FinOps, and extend the FOCUS billing spec to into token-based models.
The backers tell you it's real. Early supporters include Accenture, Booking.com, Flexera, Google Cloud, IBM, JPMorganChase, KPMG, Microsoft, Nebius, Oracle, Salesforce, SAP, and ServiceNow. When the buyers and the suppliers both show up, a discipline is forming, not a marketing slide.
As J.R. Storment, who leads the FinOps Foundation, framed the whole thing: token costs and efficiency have become a CEO level concern, not an engineering footnote.
9. The hardest question nobody can answer yet: was the token worth it?
The most honest moment of the keynote was the admission that the answers aren't in yet. The open questions the industry now has to chew on over the next couple of years are genuinely hard.
How do you measure cost per intelligent outcome instead of cost per token?
Is intelligence per watt the right yardstick, or total cost per unit of intelligence, when sustainability and cost pull against each other?
How do you force price transparency when token rates change with no notice?
How do you price in failure and retries?
And the meta question hanging over all of it: should a human govern AI cost, or should an agent?
We know how to count tokens. We just don't yet know how to tell whether they were worth it.
10. The winners won't have the cheapest tokens. They'll see the whole stack.
Every era picks a number too early and pays for it later. Page views gave us bot farms. Downloads gave us vanity metrics. Tokenmaxxing gave us the great token panic. The difference this time is that the industry caught itself fast, named the gap, and started building the discipline to close it before the next bill lands.
Cloud cost management took years to grow into FinOps. Tokenomics is trying to do it in months, on infrastructure that stays tight until at least 2028. The teams that win won't be the ones with the cheapest tokens. They'll be the ones who can see all the way down the stack, across every cloud, and finally answer the only question that ever mattered: was it worth it.
Stop guessing where your tokens go
Seeing the whole stack is exactly the problem Amnic's AI Token Management was built to solve. The same rigor you apply to cloud costs, now for AI.
Amnic gives you full visibility into AI token usage across your organization so you can allocate costs accurately, spot inefficiencies early, and understand how and where AI is deployed.
Govern spend with budget controls. Set budget limits across teams and models to prevent runaway AI spend before it hits your invoice. Track input and output token cost trends over time to understand usage patterns and manage spend accurately.
Break down token usage across models. See exactly how usage splits across every model and provider you run, so the costliest workloads stop hiding inside a single line item.
Attribute token costs to teams, users, and more. Attribute token consumption to individual teams, users, or cost centers with precision, enabling accurate internal chargeback and accountability at scale. Get token usage down to individual users or service accounts for full organizational visibility.
Detect anomalies. Configure real-time alerts on token usage thresholds and budget limits to catch anomalous cost spikes before they compound, stopping silent overruns that traditional cloud monitoring tools miss.
It pulls usage and cost data straight from leading LLM providers like OpenAI, Anthropic, and Gemini through native API integrations, and tracks token spend alongside the rest of your cloud costs, including Amazon Bedrock, for one unified view.
The token panic caught a lot of teams flat-footed. The ones who get ahead of it will be the ones who can already see, attribute, and govern every token they spend. Book a demo or get a no-cost 30 day trial to see what that looks like for your stack.
Better visibility and management into AI Tokens?
Start with a 30 day trial
Connect leading LLMs
24 hour time to value
Stay ahead of AI Spend

Make AI spend visible, controllable, and accountable.
Gain insights into your AI token costs at a team, customer, business unit and individual user level to measure and manage AI utilization.
Recommended Articles

9 Best FinOps Tools for AI Cost Management in 2026
Read More

6 FinOps Principles and How to Apply Each One
Read More

FinOps FOCUS: A Complete Guide to the Open Cost and Usage Specification in 2026
Read More

Top 15 FinOps Tools for Cloud Cost Management in 2026 (Honest Review)
Read More

Best Cloud Financial Management Software in 2026: Top 7 Tools Reviewed and Compared
Read More

FinOps for Startups in the AI Era: Building Cost Discipline Before You Scale
Read More






